コーソルDatabaseエンジニアのブログ
技術ブログ
技術ブログ
目次
渡部です。 この記事は、JPOUG Advent Calendar 2020 の1日目の記事です。
IT業界では、在宅勤務の方も多いかと思います。 在宅勤務によってできた「通勤時間分の空き時間」を使って、何か有意義なことができないか? を考えた結果、英語の勉強も兼ねて英語のYouTubeビデオをたまに見るようになりました。
しかし、英語の勉強とはいえ、せっかくですから面白い/有益な内容のYouTubeビデオを見たいものです。
そこで、Oracleパフォーマンスチューニングスキルを高められるYouTubeビデオとして、 Oracle Real-World Performance Video Seriesをご紹介します。
YoutubeプレイリストOracle Real-World Performance Video Seriesに含まれるビデオの一覧を以下に示します。
Oracle Real-World Performance Video Series のスピーカーであるAndrew Holdsworthさんは英語をゆっくり話してくれるので、 比較的聞き取りやすいと思うのですが、英語が苦手な私にとってはそれでも難しい。

そんな場合でも、Youtubeの速度調整機能を使えば、ゆっくりとした再生にでき、英語を聞き取りやすくなります。
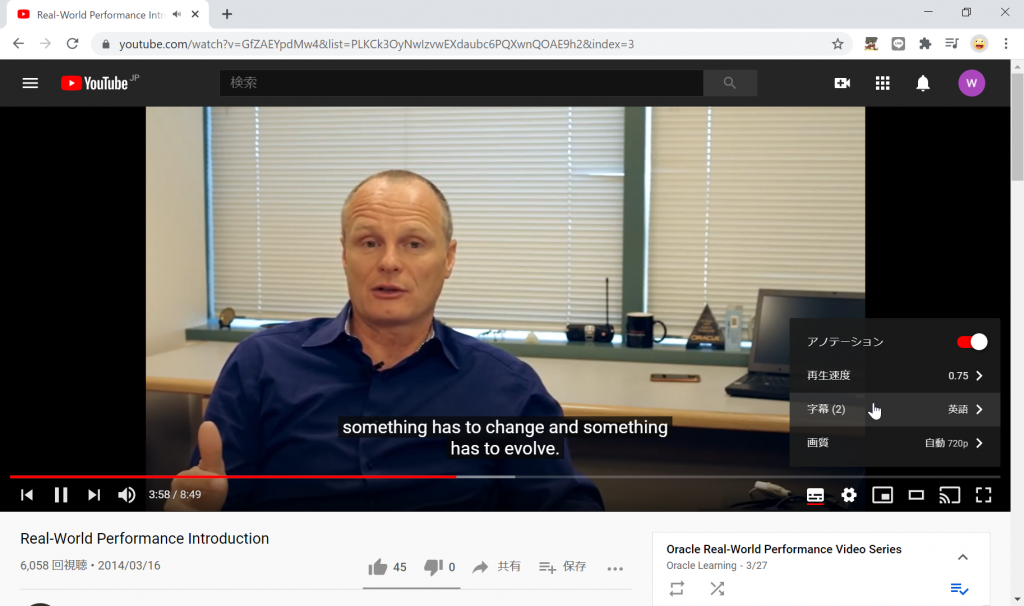
さらに、自動生成された字幕を表示すると、聞き取りにくい単語や連語もちゃんとわかります 🙂
英語学習にはありがたい機能です!
すべてのビデオの内容を説明!と行きたいところですが、全部で27本あるビデオを説明するのは厳しいので・・・
について説明したいと思います。
なお、このビデオの内容を理解すると、実は、同じアプローチで説明している以下の3つビデオも理解できます。
では、外部データのローディングを、以下の4つのアプローチで用いて実行した場合の処理速度を比較しています。
以下に、上記4つのアプローチを用いてローディング処理を実行した場合の処理速度を示します。
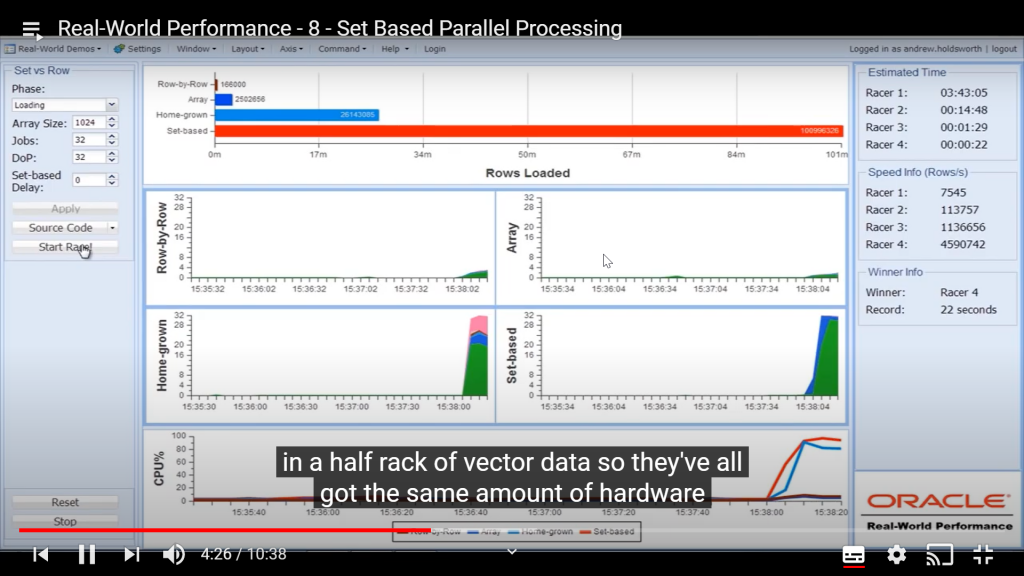
"Estimated Time"がそれなのですが、
Racer 1: 03:43:05 (=Row-by-Row)
Racer 2: 00:14:48 (=Array)
Racer 3: 00:01:29 (=Home-grown)
Racer 4: 00:00:22 (=Set-based)なので、Set-basedアプローチ、すなわちOracleのパラレル機能を使用したローディング処理が圧倒的に速いですね。
アプローチにつけられた名称だけではピンと来ないと思うので、 各アプローチの処理イメージを示すPL/SQLおよびSQLのソースコードを以下に示します。
なお、これらのソースコードはYoutubeビデオに表示されたものを転記し、 それに対して、渡部が処理内容を説明するコメント追記したものです。
Source code for Loading, using Row-by-Row technique
Row-by-Rowのソースコードです。1行ずつ処理するアプローチです。
declare
cursor c is select s.* from ext_scan_events s;
r c%rowtype;
begin
open c;
loop
fetch c into r; -- 外部表 ext_scan_events から1行読み取る
exit when c%notfound;
insert into stage1_scan_events d values r; -- 読み取った1行をテーブル stage1_scan_events にINSERTする
commit; -- 1行INSERTするたびにCOMMITを実行
end loop;
close c;
end;なお、外部表はOracleデータベース外部のファイルを表のようにSQLでアクセスできるようにする、Oracle Databaseの機能です。
Source code for Loading, using Array technique
declare
cursor c is select s.* from ext_scan_events s;
type t is table of c%rowtype index by binary_integer;
a t;
rows binary_integer := 0;
begin
open c;
loop
fetch c bulk collect into a limit array_size; -- 複数の行を外部表 ext_scan_events から配列 a に一括で読み取る
exit when a.count = 0;
forall i in 1..a.count
insert into stage1_scan_events d values a(i); -- 配列 a の行をテーブル stage1_scan_events にINSERTする
commit; -- 配列 aに読み取った複数行をINSERTしたあとでCOMMITを実行
end loop;
close c;
end;上記処理のポイントは以下です。
Source code for Loading, using Home-grown technique
"Home-grown"のソースコードです。アプリケーション側で実装したパラレル機構で処理するアプローチです。
declare
sqlstmt varchar2(1024) := q'[ -- 実行する一連のSQLを文字列 sqlstmt として定義
-- BEGIN embeded anonymous block
cursor c is select
s.*
from
ext_scan_events_${thr} s; -- スレッド番号thrを後置きした外部表からデータを読み取る
type t is table of c%rowtype index by binary_integer;
a t;
rows binary_integer := 0;
begin
for r in (select
ext_file_name
from
ext_scan_events_data
where ora_hash(file_seq_nbr,${thrs}) = ${thr}) --
loop
(略)残念ながらソースコードのすべての部分がビデオに表示されないため、正確なところはわかりませんが、 おそらく以下の仕組みを前提に動作するものと思われます。
Source code for Loading, using Set-based technique
"Set-based"のソースコードです。Oracleのパラレル機能を使用して処理するアプローチです。
alter session enable parallel dml; -- DML処理のパラレル化を有効に
insert /*+ APPEND */ into -- ダイレクトパスロードを有効に
stage1_scan_events d
select
s.*
from
ext_scan_events s;
commit;ビデオ12~14についても簡単に説明を書きたいと思いますが、 処理速度比較と"Set-based"のソースコードを示すにとどめます。
これで、具体的な処理の内容と"Set-based"の効果は十分お伝えできると考えています。
重複データの排除を、4つのアプローチで用いて実行した場合の処理速度の比較は以下です。
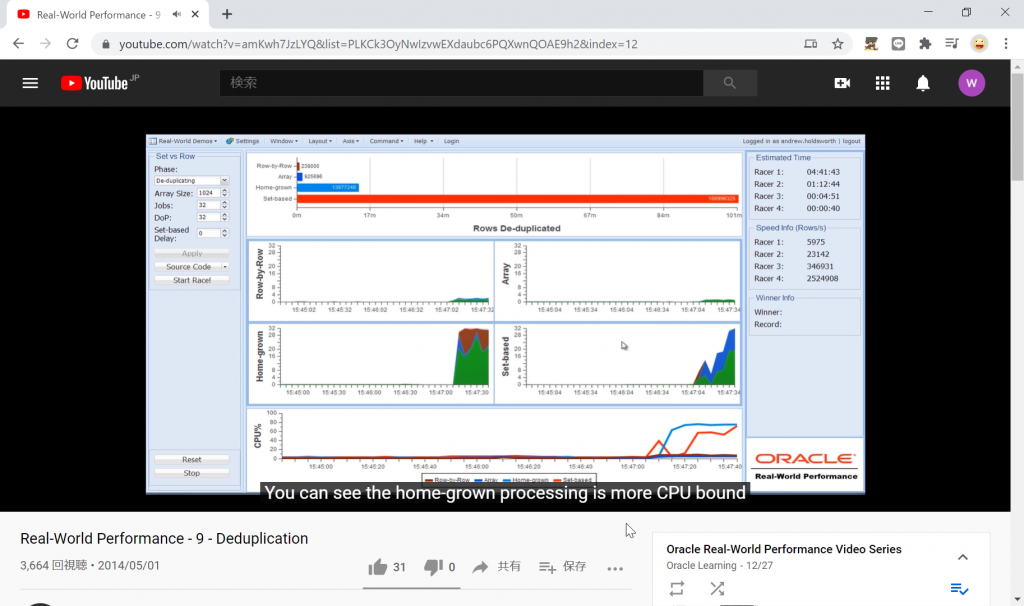
"Estimated Time"を以下に転記します。
Racer 1: 04:41:42 (=Row-by-Row)
Racer 2: 01:12:44 (=Array)
Racer 3: 00:04:51 (=Home-grown)
Racer 4: 00:00:40 (=Set-based)"Set-based"アプローチで重複データ排除処理を実装した場合のソースコードを以下に示します。
alter session enable parallel dml; -- パラレルDMLを有効化する
insert /*+ APPEND */ first ─┐(1)
when error_ind = 1 then into │
stage2_scan_events │
values ( ... ) │
else into │
stage1_scan_evnets_err ─┘
select ─┐(2)
s.* │
,row_number() over │
( │
partition by │
loc_code, rtl_trx_seq_nbr, trx_line_item_seq_nbr │
order by │
file_seq_nbr desc, rowid │
) as error_ind │
, rowid as rid │
from │
starge1_scan_events_ref s; ─┘
commit;処理のポイントを以下に示します。
データ変換を、4つのアプローチで用いて実行した場合の処理速度の比較は以下です。
![]()
"Estimated Time"を以下に転記します。
Racer 1: 05:04:60 (=Row-by-Row)
Racer 2: 00:11:04 (=Array)
Racer 3: 00:01:52 (=Home-grown)
Racer 4: 00:00:26 (=Set-based)"Set-based"アプローチでデータ変換処理を実装した場合のソースコードを以下に示します。
alter session enable parallel dml;
insert /*+ APPEND */ first ─┐(4)
when error_ind = 0 then into │
stage3_scan_events │
values ( ... ) │
else into │
stage2_scan_evnets_err │
values( ... ) ─┘
with ─┐(1)
dim_day_current │
as (select * from dim_day where day_code = '20130922') ─┘
select ─┐(2)
s.* │
,d.day_key │
,l.loc_key │
,p.prod_key │
,( ─┐(3)│
case when day_key is not null then 0 else 1 end │ │
+ case when loc_key is not null then 0 else 2 end │ │
+ case when prod_key is not null then 0 else 4 end │ │
) as error_ind ─┘ │
from │
stage2_scan_events_ref s │
left outer join │
dim_day_current d │
on s.day_code = d.day_code │
left outer join │
dim_loc l │
on s.loc_code = l.loc_code │
left outer join │
dim_prod p │
on s.prod_code = p.prod_code; ─┘
commit;処理のポイントを以下に示します。
集計を、4つのアプローチで用いて実行した場合の処理速度の比較は以下です。
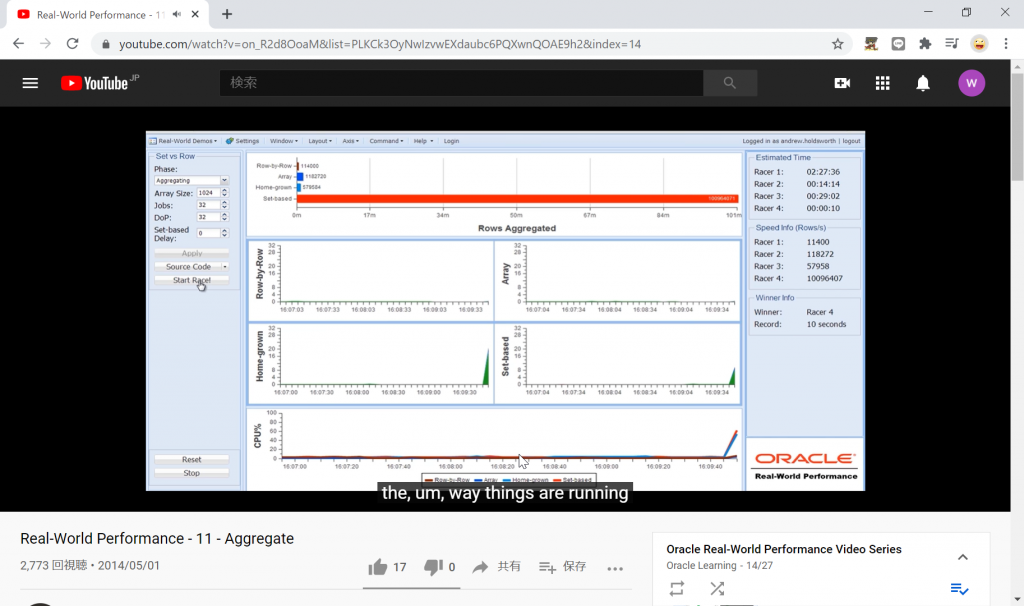
"Estimated Time"を以下に転記します。
Racer 1: 02:27:36 (=Row-by-Row)
Racer 2: 00:14:14 (=Array)
Racer 3: 00:29:02 (=Home-grown)
Racer 4: 00:00:10 (=Set-based)"Set-based"アプローチで集計処理を実装した場合のソースコードを以下に示します。
alter session enable parallel dml;
insert /*+ APPEND */ into
fact_sales d
select
day_key
,loc_key
,prod_key
,sum(case when actn_code = 'Sale' then 1 else -1 end * qty ) as qty ─┐(1)
,sum(case when actn_code = 'Sale' then 1 else -1 end * extend_amt ) as extended_amt │
,sum(case when actn_code = 'Sale' then 1 else -1 end * │
extend_amt * (100 - discount_pct ) / 100) as discount_amt ─┘
from
stage3_scan_events_ref s
group by
day_key
,loc_key
,prod_key;
commit;処理のポイントを以下に示します。
明日のJPOUG Advent Calendar 2020 の担当はs4r_agentさんです。s4r_agentさん、よろしくお願いします 🙂



渡部 亮太
・Oracle ACE
・AWS Certified Solutions Architect - Associate
・ORACLE MASTER Platinum Oracle Database 11g, 12c 他多数
2024年
2023年
2022年
2021年
2020年
2019年
2018年
2017年
2016年
2015年
2014年
2013年
2012年
2000年