技術ブログ
目次
渡部です。Oracle DatabaseだけではなくMySQLやPostgreSQLを含めた複数のRDBMS製品の使用経験があるエンジニアがとても増えているように感じます。 以前は、エンタープライズIT業界におけるRDBMSといえばOracle Database一択でしたが、オープンソースDBの高機能化・高信頼性化と、ライセンスコスト削減圧力の高まりにより、MySQLやPostgreSQLを始めとするオープンソースDBが採用されるケースも出てきています。クラウド化も影響している部分があります。
それぞれのRDBMS製品は大枠では似ていますが、違う部分も意外と多いです。 あるRDBMSの知識を生かすことで、他のRDBMSについて早く理解できる場合もありますが、 逆に、あるRDBMSの知識が邪魔になり、他のRDBMSについての理解を妨げる場合もあります。
ここで紹介する「バックアップと障害復旧から考えるOracle Database, MySQL, PostgreSQLの違い」 は、バックアップと障害復旧の観点から、RDBMSの違いについて理解を深めるために作成した資料です。
この資料は結構好評で、以下の2つのイベントでお話させていただきました。 そして、資料は2016年に作成したものですが、現在でも通用する内容なはずです。
また、 Database Lounge Tokyo #2で発表したときの動画もあります。(尺が長いので通しで視聴するのは辛いですが・・・)
RDBMSにとって、データの保護とサービスの継続が最も重要な責務です。 このため、たいていのRDBMSにおいて、バックアップと復旧の機能には以下の特徴があります。
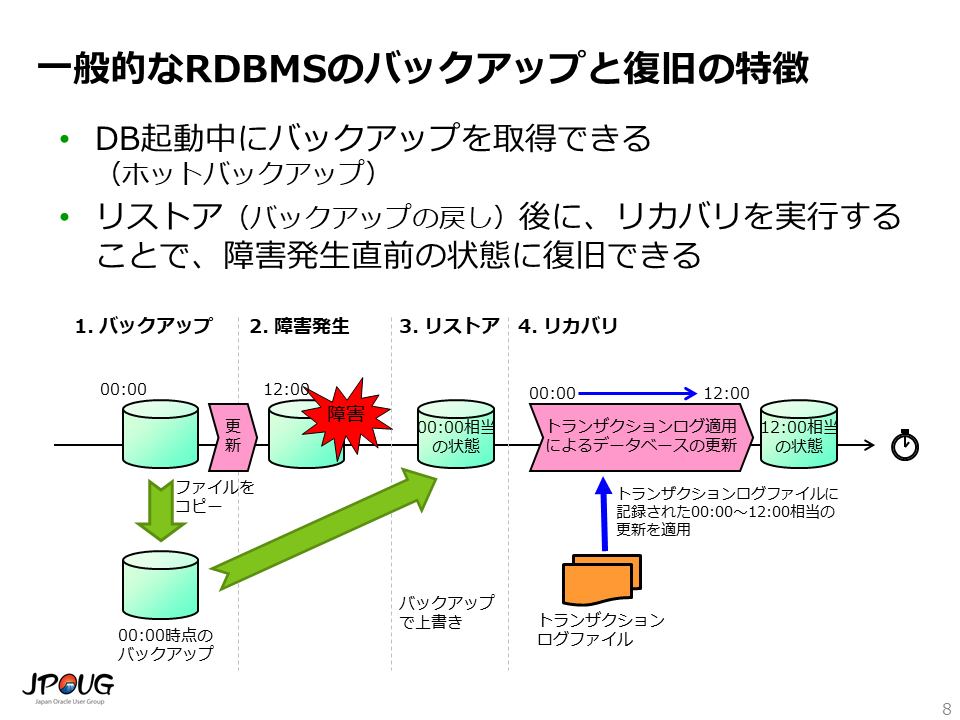
ホットバックアップ機能がないと、バックアップを取得するたびにデータベースを停止する必要がでてきます。これは通常のシステムでは受け入れられない制限です。
また、リカバリ機能がないと、障害発生時にバックアップ取得時点の状態にしか復旧できないことになります。これも、通常のシステムでは到底受け入れられない制限です。 リカバリ機能があると、障害発生直前の状態にまでデータを復旧することができます。
この機能は非常にパワフルです。ファイルサーバとRDBMSを比較する形で考えてみましょう。
ファイルサーバ(のバックアップ)にはリカバリ機能はありません。 このため、バックアップ取得時点の状態にしか復旧できません。たとえば、毎晩深夜00:00にバックアップを取得しており、昼の12:00に障害が発生した場合、バックアップ取得時点の状態、すなわち昨夜00:00の状態にしか復旧できません。昨夜00:00から昼の12:00の間に実行された更新はすべて失われることになります。
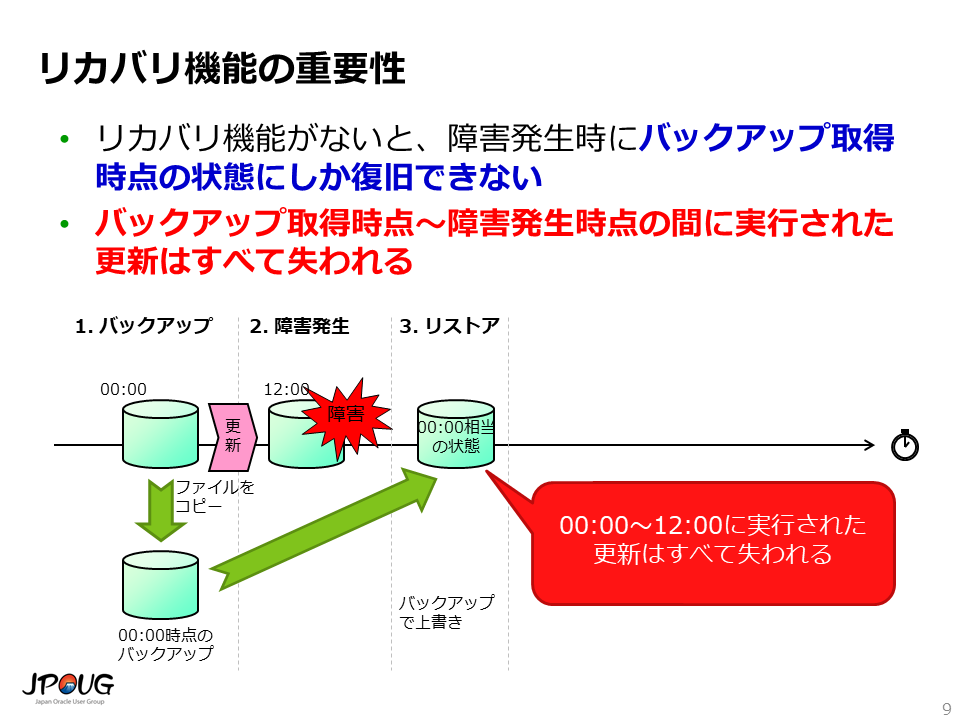
逆にリカバリ機能があれば、昼の12:00の状態に復旧することができます。
RDBMSのリカバリ機能を可能にしているのがトランザクションログです。
RDBMSに格納されたデータは、データファイルに記録されています。 よって、データを更新すると、更新後のデータがデータファイルに書き込まれます。 しかし、それに加えて、データの更新記録がトランザクションログファイルというファイルにも追記書き込みされるのです。
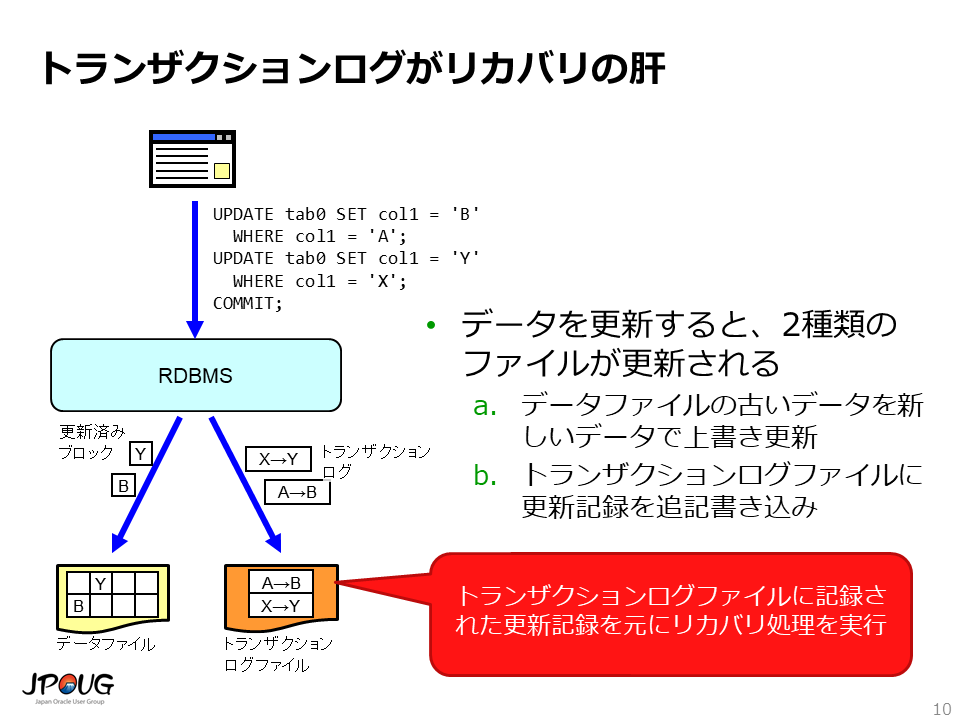
これにより、トランザクションログファイルには、データベースに加えられた全ての変更が記録されることになります。これがリカバリ処理の元ネタになります。
障害発生時は、リストア(バックアップファイルの戻し)を行ったあと、 トランザクションログファイルにに記録された更新記録を元にリカバリ処理を実行することになります。
なお、「トランザクションログファイル」という呼び名は、特定の製品に依存しない一般的な文脈におけるものです。「トランザクションログファイル」に相当する概念は、製品ごとに異なります。例えば、Oracle Databaseにおける「トランザクションログファイル」は「オンラインREDOログファイル」および「アーカイブREDOログファイル」です。PostgreSQLにおける「トランザクションログファイル」は「WALログファイル」です。
ここまでは、特定の製品に依存しない一般的な説明でした。 徐々に製品固有の説明に移りたいと思いますが、その前に 特定の製品に依存しない形でのRDBMSのアーキテクチャを説明しておきたいと思います。
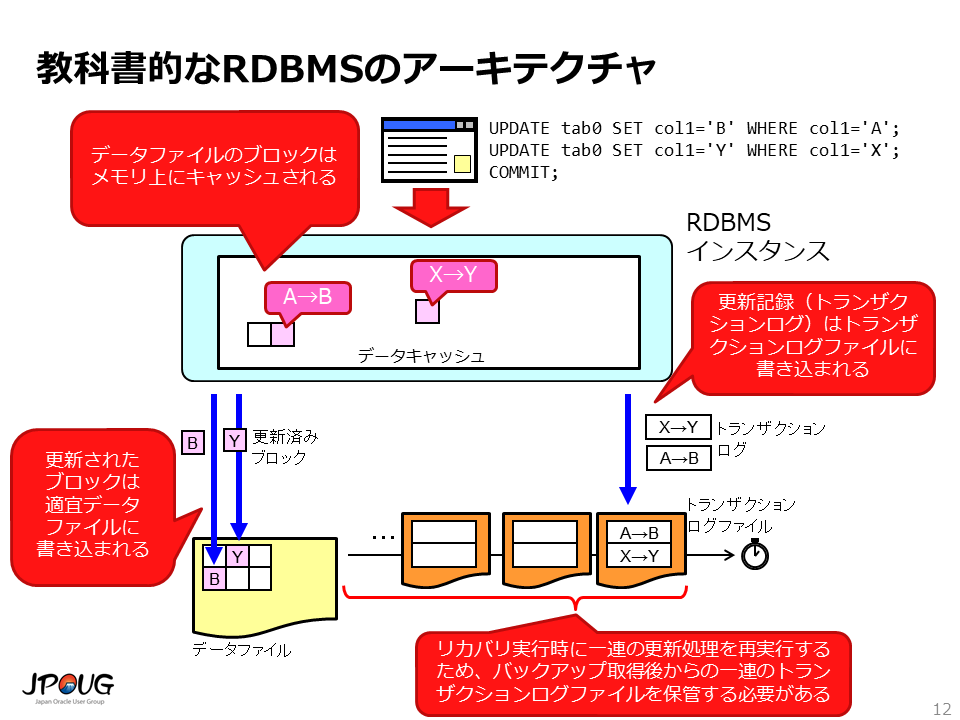
ポイントを抜粋しておきます。
Oracle Databaseのアーキテクチャは、先ほど説明した教科書的なRDBMSのアーキテクチャにかなり似ています。
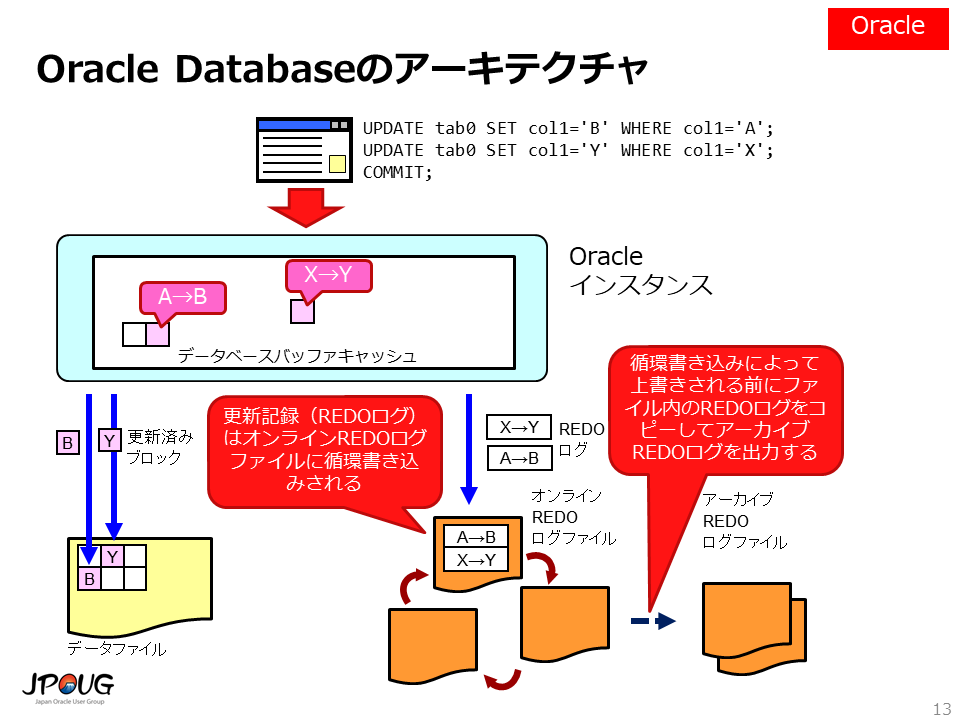
以下の点に注意して下さい。
PostgreSQLのアーキテクチャも、先ほど説明した教科書的なRDBMSのアーキテクチャにかなり似ています。
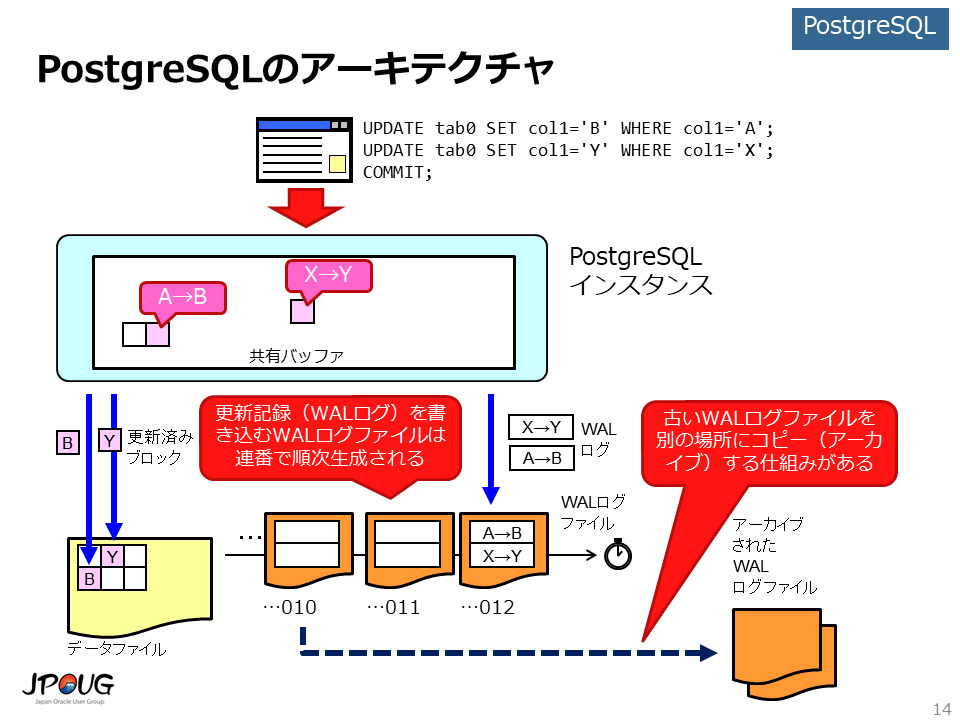
以下の点に注意して下さい。
ストレージエンジンにInnoDBを使用する場合のMySQLのアーキテクチャは以下の通りです。
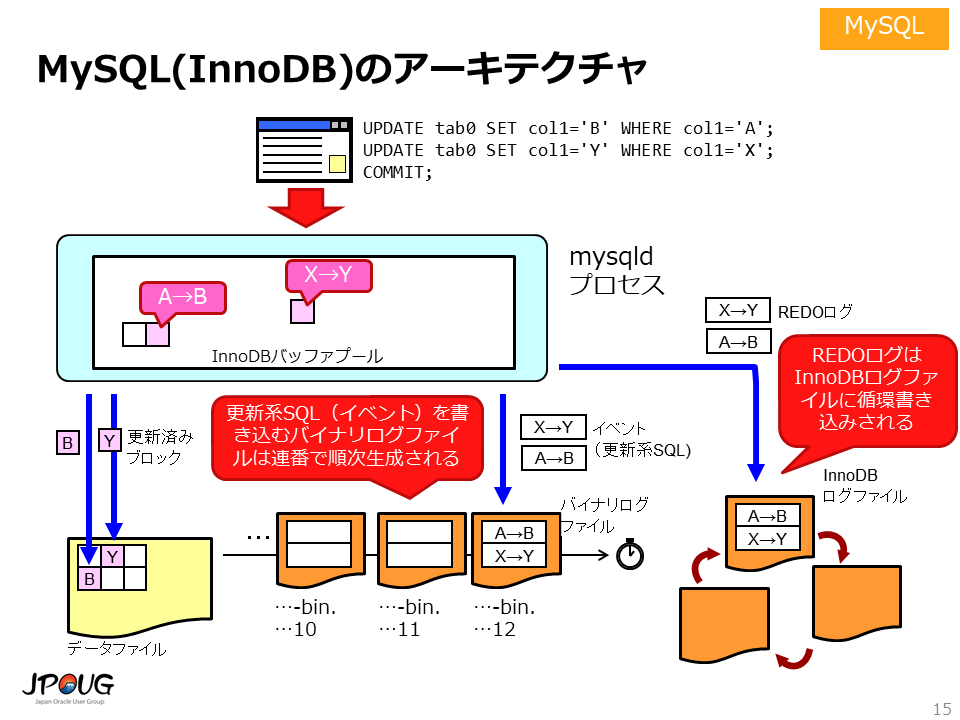
トランザクションログに相当するファイルが2種類ある(バイナリログファイルとInnoDBログファイル)点で、若干ユニークなアーキテクチャになっています。
なお、MySQLでは、InnoDB以外のストレージエンジンも使用できます。 本資料では、ストレージエンジンにInnoDBを使用する前提で記載しています。 現在は、たいていのシステムでストレージエンジンにInnoDBを使用しますので、これは妥当な前提です。
さて、これから、それぞれのRDBMS製品についてバックアップと復旧の動作についてみていきます。 最初に、教科書に忠実な一般的なモデルとして、Oracle Databaseのバックアップと復旧から見てゆきたいと思います。
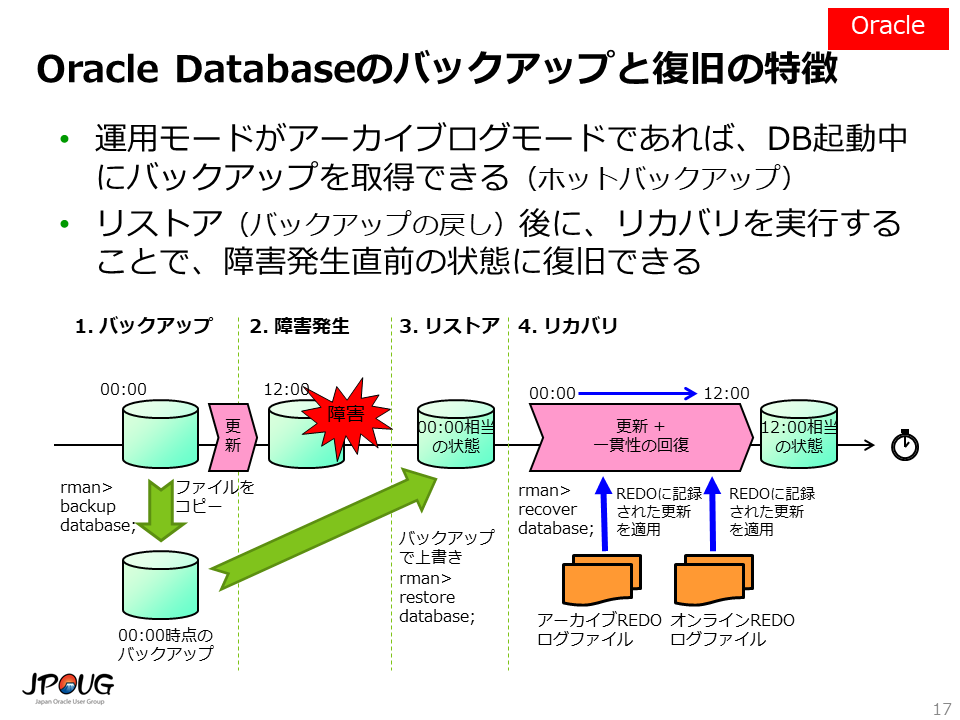
先に説明した「前提知識:RDBMSのバックアップと復旧について」の図と非常に似ていることが分かります。 Oracle Databaseは、リレーショナルデータベースの知見を基にして素直に実装されていると言えるかもしれません。
ここまで、リカバリ処理の目的として、 「バックアップ取得時点~障害発生直前までにデータベースに加えられた更新処理を(再)実行する」 点を強調して説明してきました。
しかし、Oracle Database(および一般的なRDBMS)においては、リカバリ処理に別の重要な役割があります。それは、「一貫性を回復する」ということです。
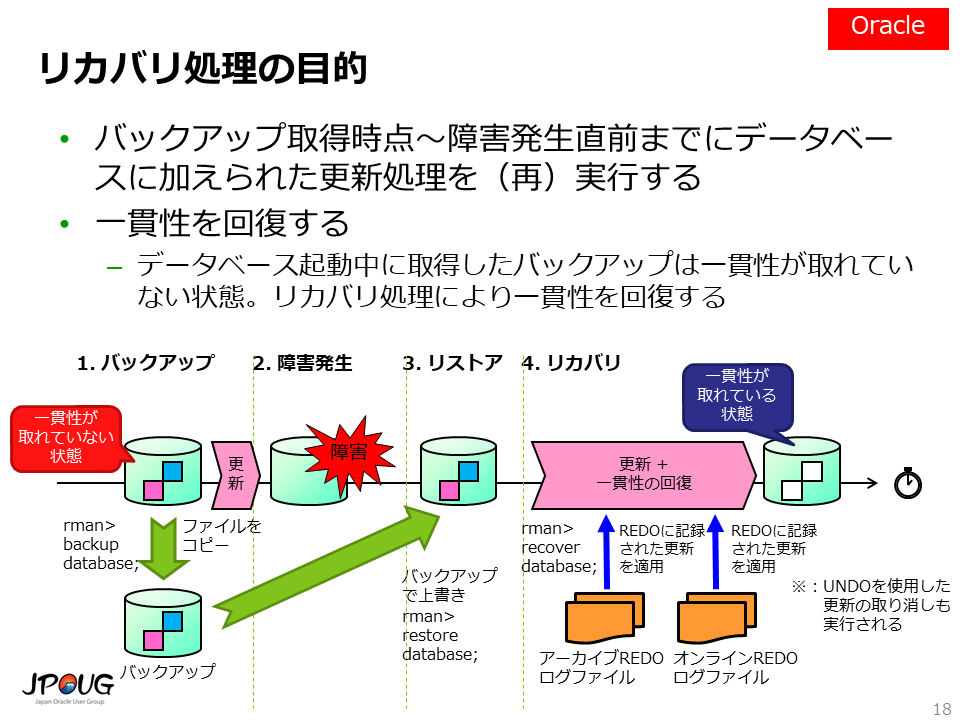
データベースは停止することが通常許されませんから、たいていの場合、起動中にバックアップを取得します。 もちろんOracle Databaseは起動中にバックアップを取得できますが、データベース起動中に取得したバックアップは一貫性が取れていない状態であり、このままの状態では使えません。 具体的には、更新を取り消す必要があるブロックと、まだ更新が行われていない古いブロックが混在しているような状況にあります。
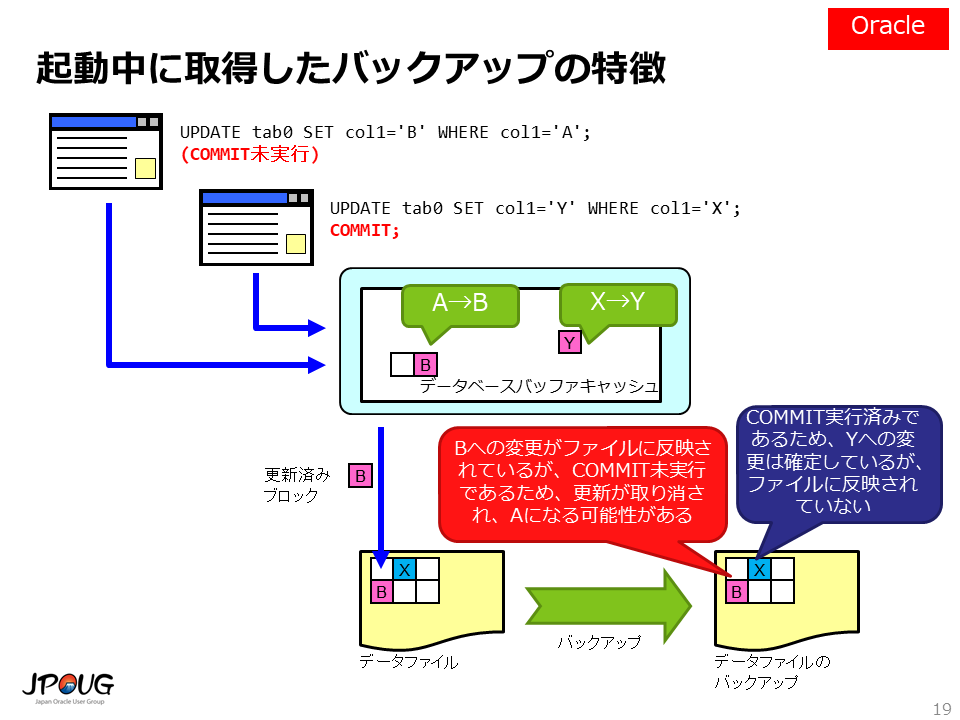
リカバリ処理を実行することで一貫性を回復し、バックアップが使えるようになります。
これまでにOracle Databaseのバックアップと復旧について説明したことをまとめると、以下の様になります。

Oracle Databaseのリカバリ処理には、1) データベースを障害発生直前の状態に進める機能と、2) 一貫性が取れていないデータベースを一貫性が取れた状態に復元する機能 の2つが含まれる点に注意してください。
次にMySQLのバックアップと復旧についてみてゆきます。
この資料では、MySQLのCommunity Editionを使用していることを前提に説明していることに注意してください。
MySQL Community Editionでのバックアップと復旧のポイントは以下の通りです。
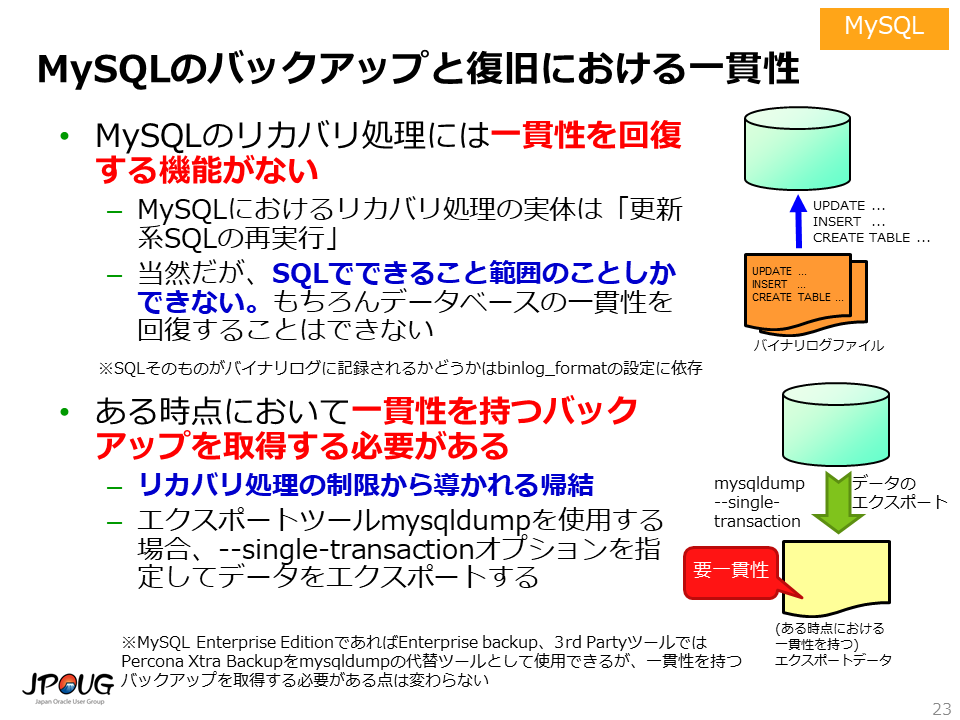
MySQLでも、Oracle Databaseと同様に起動中にバックアップを取得できます。 ただし、MySQLではバックアップは一貫性を持つ形で取得する必要があります。 ここでの「一貫性」とは、ある特定時点のデータ断面のようなイメージで捉えてもらえると理解しやすいはずです。
MySQLで、バックアップを一貫性を持つ形で取得しなければならない理由は、MySQLのリカバリ処理には一貫性を回復する機能がないためです。
MySQLにおけるリカバリ処理の実体は「更新系SQLの再実行」に過ぎません。 Oracle Databaseのリカバリ処理には、1) データベースを障害発生直前の状態に進める機能と、2) 一貫性が取れていないデータベースを一貫性が取れた状態に復元する機能 の2つが含まれましたが、MySQLには、2) 一貫性が取れていないデータベースを一貫性が取れた状態に復元する機能 がありません。
これは、MySQLのリカバリ処理の実体が「更新系SQLの再実行」であることから論理的に明らかです。MySQLのリカバリ処理は、SQLでできること範囲のことしかできません。 Oracle Databaseのリカバリ処理のような、ブロック単位の一貫性回復処理を行って、データベースの一貫性を回復することはできないわけです。
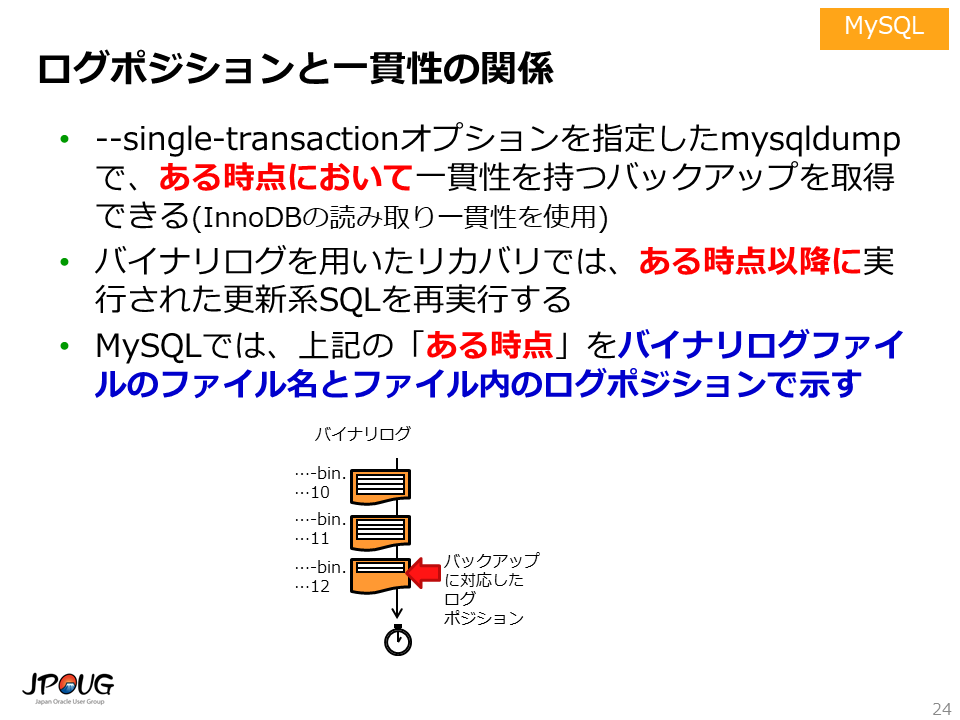
MySQLのバックアップと復旧という文脈における「一貫性」とは、ある特定時点のデータ断面のようなイメージです。そして、この「一貫性」の文脈における「特定時点」とは、ログポジションという概念を用いて示されます。
--single-transactionオプションを指定してエクスポートツール mysqldumpを実行すると、特定時点において一貫性を持つバックアップを取得できます。 取得したバックアップのダンプファイルには、その「特定時点」に対応するログポジションが記録されます。
復旧作業で、このバックアップをリストア(ダンプファイルをインポート)した後は、 バイナリログを用いたリカバリ処理を実行することになりますが、 「特定時点」以降に実行された更新系SQLを再実行します。具体的には、バックアップの一貫性に対応するログポジション以降に実行された更新系SQLを再実行します。
MySQLにおけるバックアップと復旧の全体の流れを示したのが、以下の図です。
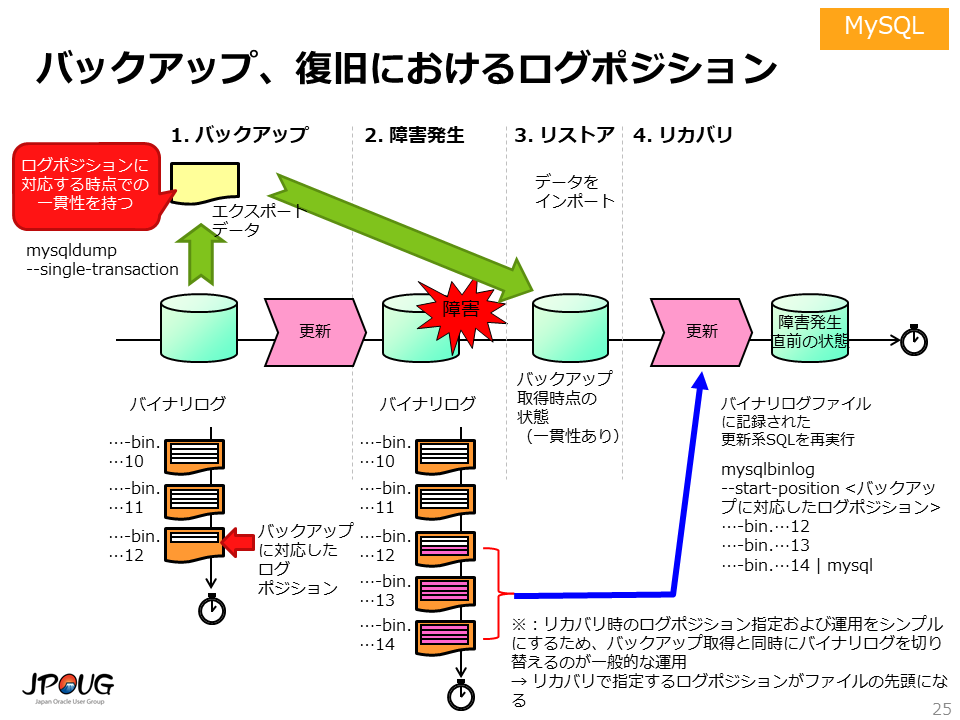
なお、この図では、ログポジションの役割を強調するため、 リカバリで指定するログポジションをバイナリログファイルの途中にしていますが、 一般的な/実務レベルの運用では、リカバリで指定するログポジションがファイルの先頭になるようにします。 バックアップ取得と同時にバイナリログを切り替えるようにすることで、これを実現できます。
MySQL(InnoDB)のアーキテクチャの箇所で、 MySQLには、トランザクションログファイルに相当するファイルとして、バイナリログファイルとInnoDBログファイルの2種類があることを説明しました。
すでに説明したように、バイナリログファイルは「更新系SQLの再実行」に使用します。 では、InnoDBログファイルはどのような役割を果たすのでしょうか。
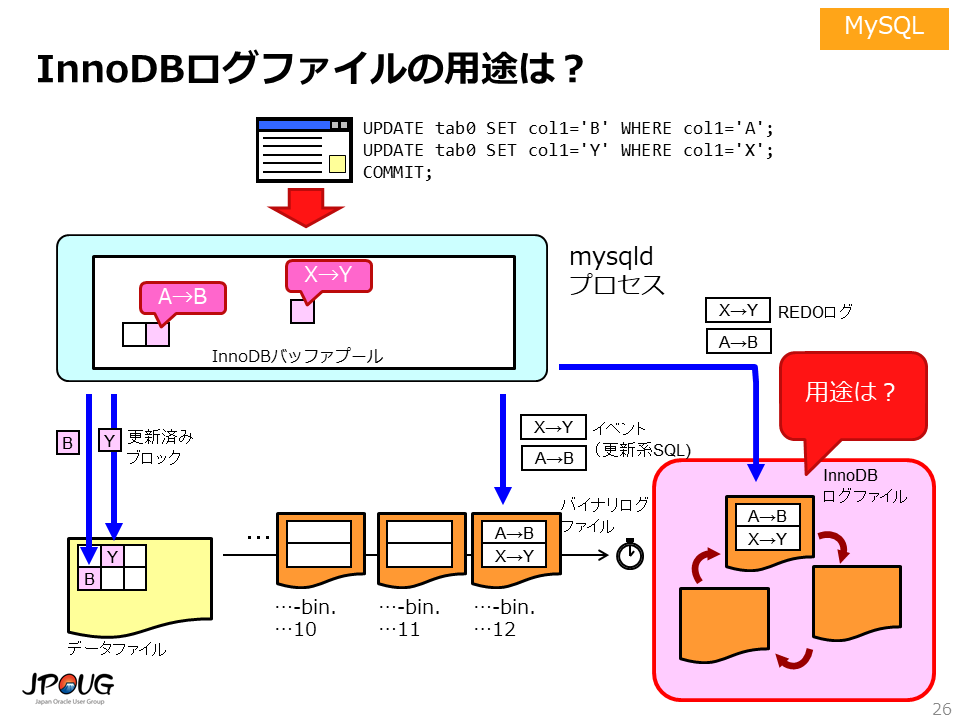
InnoDBログファイルはmysqldプロセスが異常終了したとき、データベースの一貫性を回復するために使用されます。異常終了時のデータベースの一貫性を回復する処理のことを、クラッシュリカバリと呼びます。
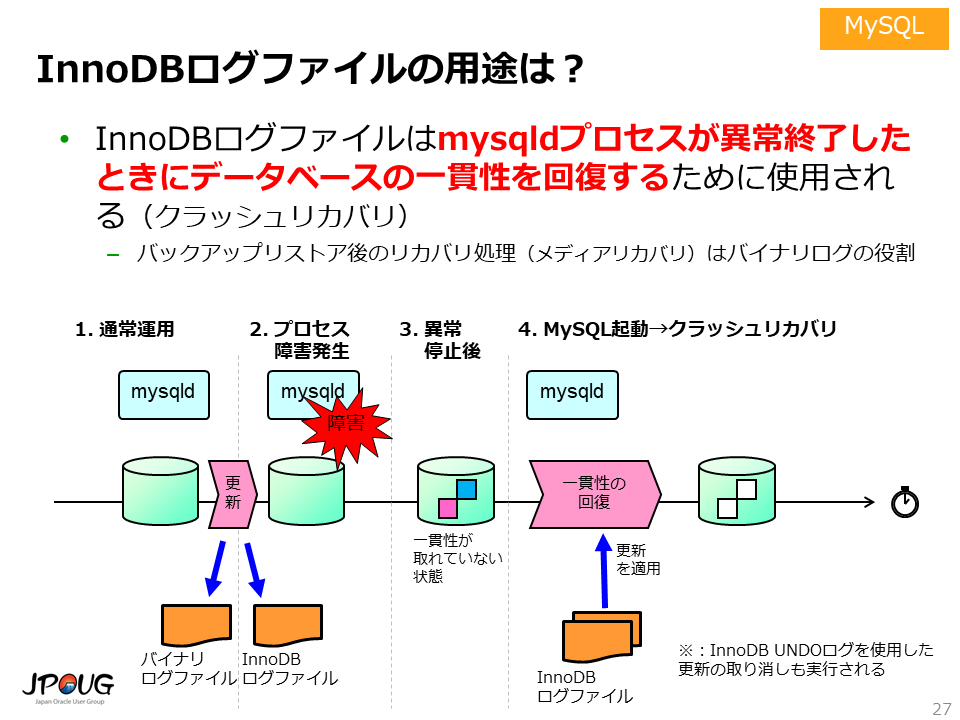
なお、バックアップリストア後のリカバリ処理はメディアリカバリと呼びます。
すなわち、メディアリカバリはバイナリログファイルの役割です。 クラッシュリカバリはInnoDBログファイルの役割です。
これまでに説明したように、MySQLのバックアップと復旧の仕組みは Oracle Databaseのバックアップと復旧の仕組みの仕組みと大きく異なります。
このため、Oracle Databaseの知識を持つエンジニアが、初めてMySQLのバックアップと復旧を学んだとき困惑するはずです。事実、私も初めてMySQLのバックアップと復旧を学んだとき、困惑し、いくつかの疑問を抱きました。
典型的な疑問とその答えを以下にまとめておきます。

最後に、PostgreSQLのバックアップと復旧の仕組みを見てゆきます。
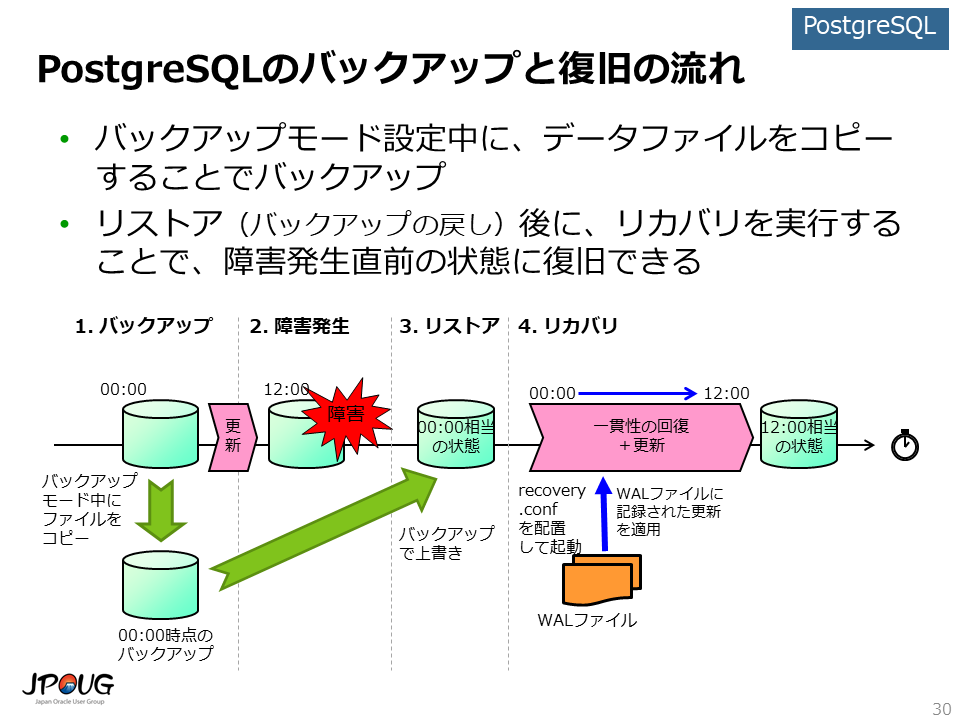
Oracle Databaseのバックアップと復旧の仕組みと同様に、教科書に忠実な一般的なモデルに似ています。
バックアップモード設定中に、バックアップを実行する必要がある点に注意してください。
PostgreSQLではリカバリ処理を実行して障害発生直前の状態に復旧できるバックアップを、ベースバックアップと呼びます。
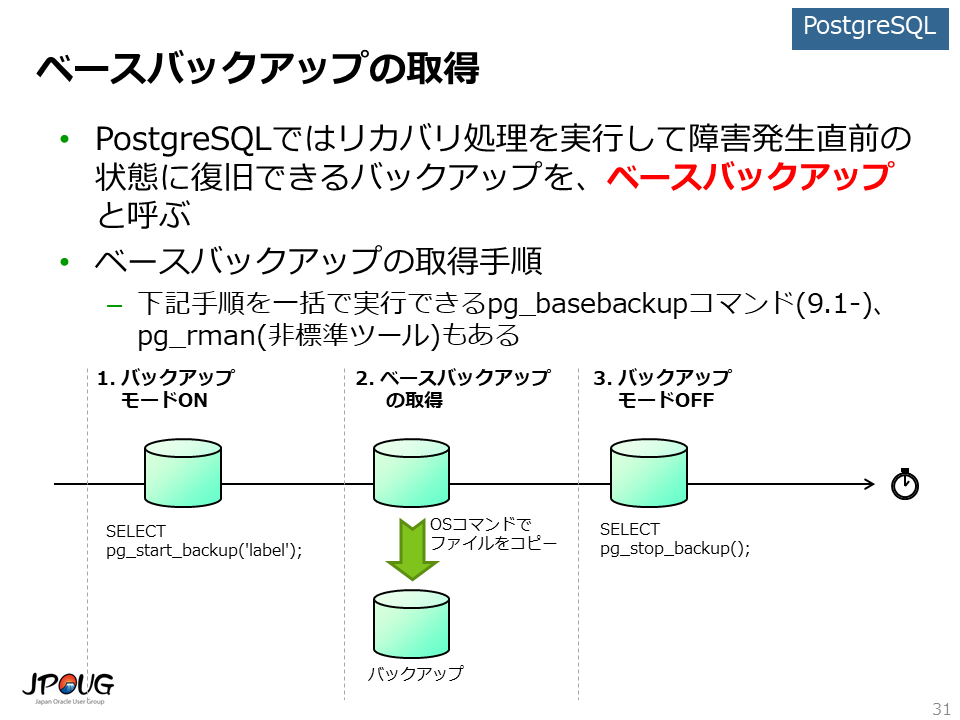
ベースバックアップの取得手順は以下の通りです。
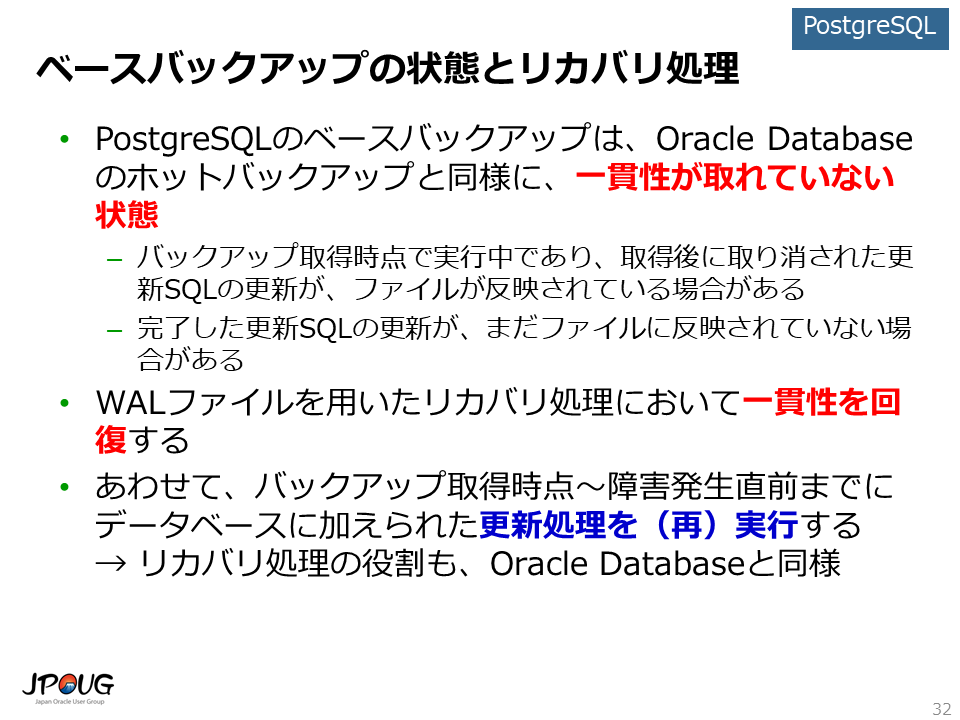
PostgreSQLのベースバックアップは、Oracle Databaseのホットバックアップと同様に、一貫性が取れていない状態です。 このため、リカバリ処理において一貫性を回復する必要があります。
最後に、データベース起動中にバックアップを取得する、ホットバックアップならではの課題へのアプローチ方法を通じて、PostgreSQLとOracle Databaseの違いに触れてみたいと思います。
データベース起動中にバックアップを取得するということは、 データベースによるデータファイルの更新と、バックアップ処理によるデータファイル読み取り(ファイルコピー)が同時に実行される可能性があるということです。
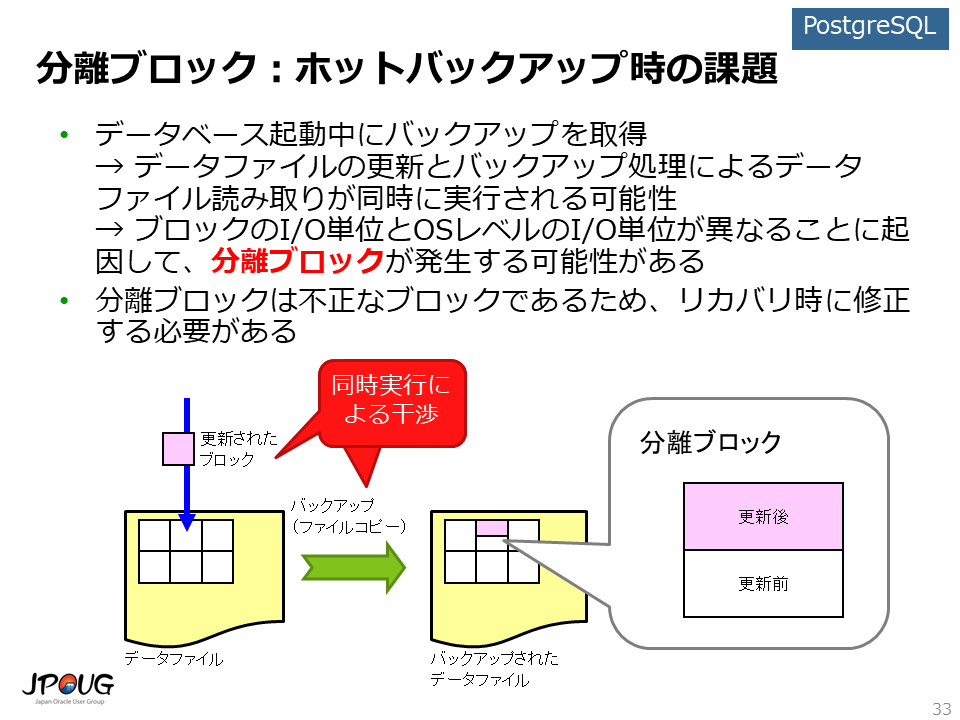
この時、それぞれの処理のI/O単位が異なる点が問題になる場合があります。 データベースは、そのデータベースのブロック単位でI/O処理を実行します。 バックアップツールを含む、データベース以外のアプリケーションは、OSのブロック単位でI/O処理を実行します。データベースのブロックのI/O単位とOSレベルのI/O単位が異なると、これにに起因して、分離ブロック(fractured block)が発生する可能性がでてきます。
分離ブロックとは、データベースによるデータファイルの更新と、バックアップ処理によるデータファイル読み取り(ファイルコピー)が干渉し、バックアップしたデータファイルに含まれる1つのブロックの中に、データベースによる更新後のデータと、更新前のデータが混在してしまったものです。 これは不正なブロックです。
なお、不正ブロックにつながる、データブロックの更新が中途半端になる現象を、"partial page write"と呼ぶことがあります。
PostgreSQLでは、分離ブロックが発生しても、リカバリ時に分離ブロックを正しいブロックに修正できる仕組みを用意しています。
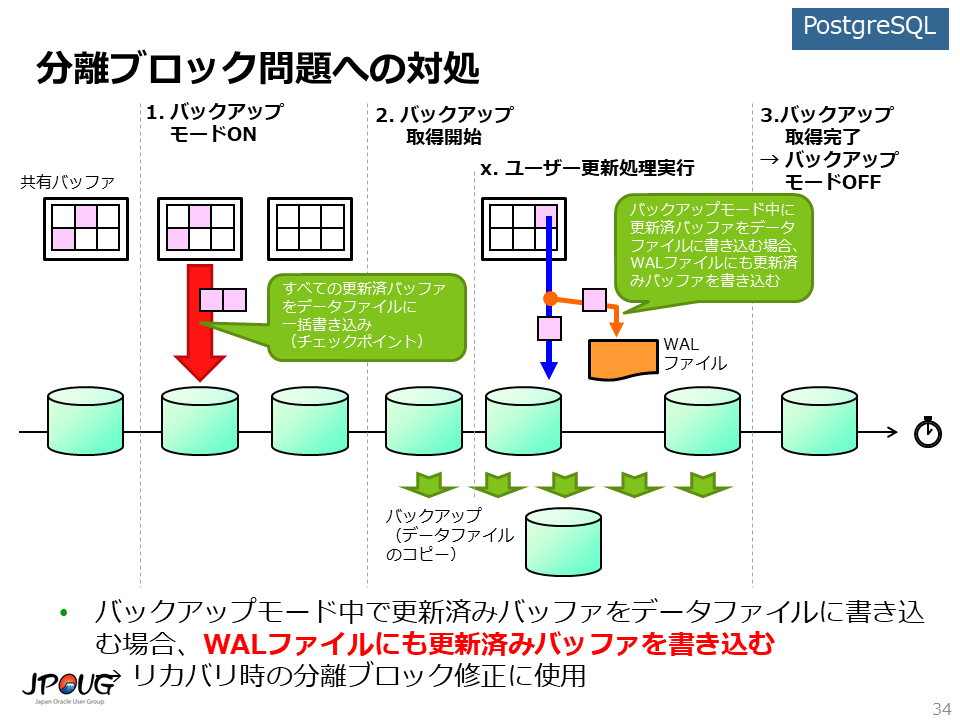
更新済みバッファとは、共有バッファにキャッシュされたブロックのうち、メモリ上で更新処理が実行されたものです。
分離ブロックが発生する可能性があるのは、更新済みバッファをデータファイルに書き込むときです。 PostgreSQLでは、そのタイミングでWALファイルにも更新済みバッファを書き込み、更新済みバッファをデータファイル以外に保管することで、リカバリ時に分離ブロックを正しいブロックに修正できるようにしています。
Oracle Databaseでも、ホットバックアップは実行できます。 では、Oracle Databaseでは分離ブロック問題にどのように対処しているのでしょうか。
実は、RMANを用いてバックアップすると、分離ブロックは発生しません。 RMANは、Oracle Database自体に実装されたバックアップの仕組みであり、 Oracle Database本体によるデータファイルの更新と競合しない仕組みが実装されているからです。
なお、RMANが導入される前のOracle DatabaseではPostgreSQLと同様の仕組みで分離ブロックに対処していました。 バックアップモード中は更新済みバッファをオンラインREDOログファイルに格納し、リカバリ時に分離ブロックを修正していたのです。

大昔からのOracle Databaseエンジニアはご存知かもしれませんが、BEGIN BACKUP; ~ END BACKUP;の話です。 🙂
PostgreSQLのバックアップモードON~OFFが、Oracle DatabaseのBEGIN BACKUP; ~ END BACKUP; に対応するというわけです。
以上、バックアップと障害復旧の観点から、Oracle Database, MySQL, PostgreSQLの違いについて説明してきました。ベースとなる考え方はある程度類似していますが、細かい部分を見てゆくと、製品ごとにかなり違いがある点が分かったかと思います。
筆者(渡部)はOracle Databaseを専門的に扱う仕事をしています。 MySQL, PostgreSQLについても仕事でそれなりに経験はありますが、正直ここ2,3年ほどはあまりMySQL, PostgreSQLを使っていません。もし、MySQL, PostgreSQLに関する記述について進化した点・変更された点があれば教えて頂けると助かります。m(_ _)m



プロフィール
渡部 亮太
・Oracle ACE
・AWS Certified Solutions Architect - Associate
・ORACLE MASTER Platinum Oracle Database 11g, 12c 他多数
カテゴリー
アーカイブ
2026年
2025年
2024年
2023年
2022年
2021年
2020年
2019年
2018年
2017年
2016年
2015年
2014年
2013年
2012年
2000年