技術ブログ
目次
渡部です。システム間データ連携の必要性が高まっていることを受け、 ロジカルレプリケーション製品に関するお問い合わせが増えています。
そこで、ロジカルレプリケーションについて説明した過去発表(db tech showcase Tokyo 2018 レプリケーション製品比較 / コーソル「DBAの窓口」presents ロジカルレプリケーションの動作の仕組みから見るOracleレプリケーション3製品のイチオシポイント)を紹介したいと思います。
ロジカルレプリケーションは非常に複雑な技術です。お客様に最適なロジカルレプリケーション製品をご案内できるよう、コーソルでは複数のロジカルレプリケーション製品を取り扱っています。
これらすべての製品について、製品を熟知したエンジニアが設計・導入作業を担います。 Oracleのロジカルレプリケーションをご検討の際はぜひコーソルにお声がけください。
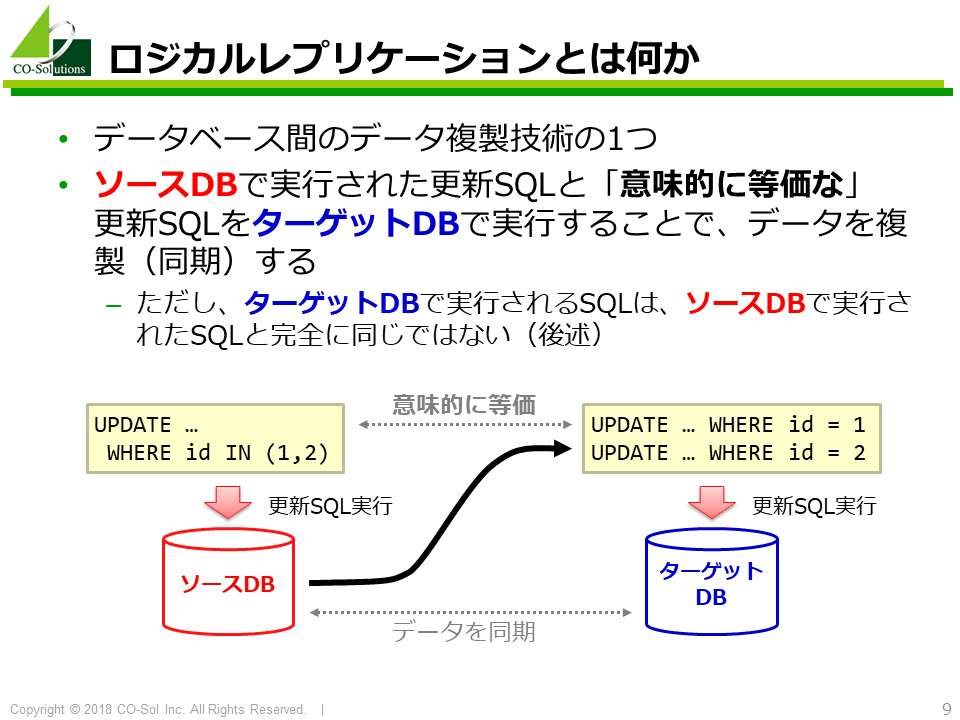
ロジカルレプリケーションとはデータベース間のデータ複製技術の1つです。 論理レプリケーションと呼ばれることもあります。
論理レプリケーションがデータを複製する仕組みは、概念的にはシンプルです。 ソースDBで実行された更新SQLと「意味的に等価な」更新SQLをターゲットDBで実行することで、データを複製(同期)します。
ただし、ターゲットDBで実行されたすべてのSQLがソースDBで実行されるわけではありません。未対応のDDLなどソースDBで実行されない=複製の対象にならないものもあります。 また、ターゲットDBで実行されるSQLは、ソースDBで実行されたSQLと完全に同じではありません。これについては後述します。
ロジカルレプリケーションはデータを連携するにはとても役立ちますが、実際に使用するには多くの考慮事項が存在する、厄介な部分もある技術です。
すでに説明した通り、ロジカルレプリケーションが基礎とする技術はSQLで、SQL実行により更新を伝搬する仕組みになっています。
このため、以下の利点を享受できます。

特に、「構成上の制約が少ない」は大きなメリットです。
ソースデータベースの製品バージョンとターゲットの製品バージョンが違ってもOKです。 すなわち、Oracle Database 11gからOracle Database 19cへレプリケーションが可能となります(もちろん、レプリケーション製品が対応している必要がありますが)。 これは、バージョンアップを伴うデータベース移行でダウンタイムを極小化したい場合にとても有用です。
ソースとターゲットが異なるデータベース製品でもOKな場合もあります。 最近は、同一の企業で様々なデータベース製品を使うのが一般的ですから、Oracle Database からMySQLやPostgreSQLなどにデータをレプリケーションできると非常に便利です。
異なるデータベースでデータ連携するとき、伝搬の元ネタがSQLな点が生きてきます。SQLは標準化されているとは言え、細部では製品固有の部分があります。 すなわち、Oracleで実行できたSQLがMySQLでエラーとなるケースがあるということです。このような状況をさけるため、ロジカルレプリケーション製品でSQLを変換できます。
データベースレプリケーション技術は、ロジカルレプリケーション方式(論理レプリケーション方式)とフィジカルレプリケーション方式(物理レプリケーション方式)の2つに大別されます。
ロジカルレプリケーション方式とフィジカルレプリケーション方式を比較したのが以下の表です。
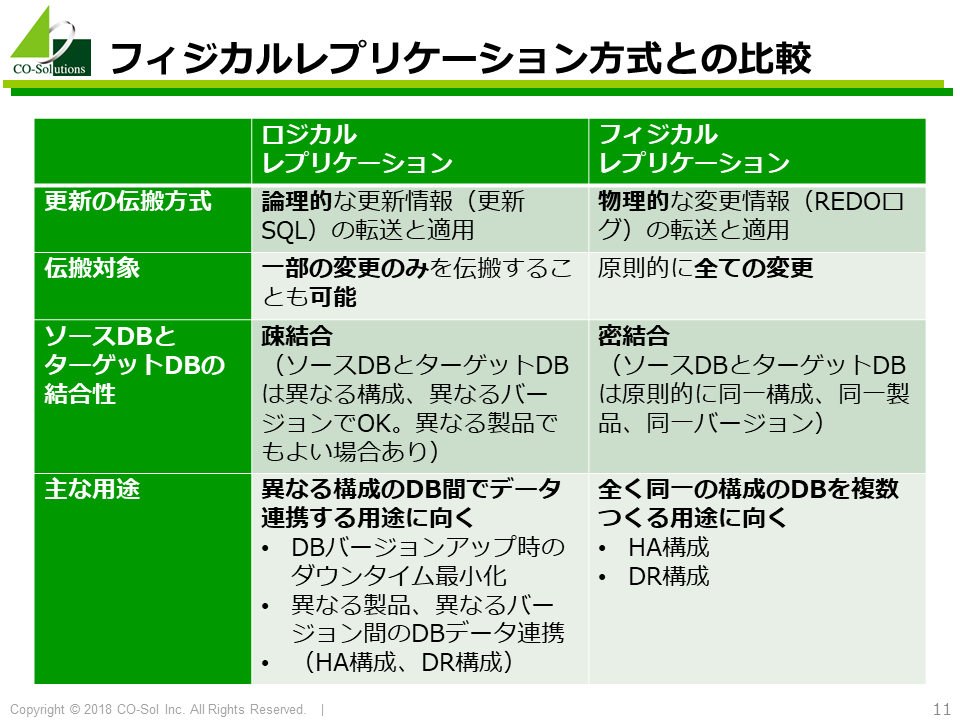
さきほど説明した利点は、フィジカルレプリケーション方式では享受することができません。 すなわち、フィジカルレプリケーション方式では、ソースとターゲットで同じデータベース製品を使う必要があります。さらに製品バージョンも同じ必要があります。また、更新伝搬時に細工を加えることはできません。プライマリDBで実行された更新と全く同じ更新がそのままスタンバイDBに伝搬されます。
なお、Dbvisit Standbyはフィジカルレプリケーション方式を用いたレプリケーション製品です。
ロジカルレプリケーションのしくみを示したのが以下の図です。
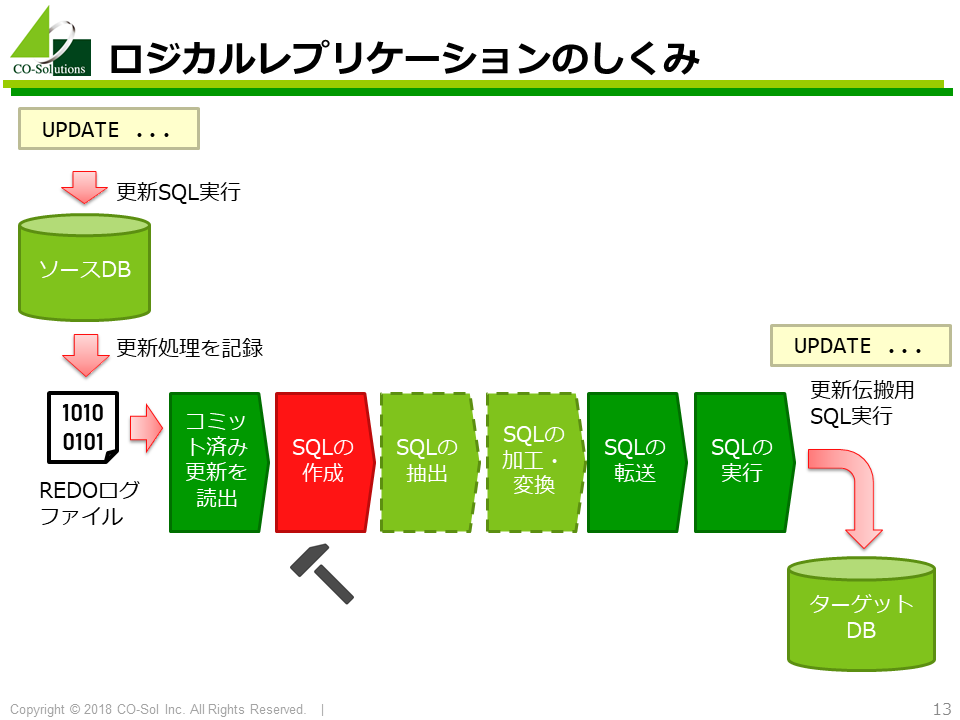
以下の処理が実行されることで、ロジカルレプリケーションが実現されます。

まず、REDOログファイル(トランザクションログファイル)からコミット済みの更新(確定した更新)を抽出して更新伝搬用SQLを作成します。
しかし、REDOログファイルには、実行された更新SQLそのものが記録されているわけではないため、 REDOログファイルに記録された更新情報から更新伝搬用のSQLを別途作成する必要があります。

REDOログファイルにはバイナリ形式のブロックレベルの更新情報が格納されていいます。 物理的な構造であるところのブロックの中の、論理的な更新情報をREDOログファイルに格納 することから、フィジオロジカルロギングと呼ばれることもあります。
ただし、通常の構成では、REDOログファイルには更新伝搬用SQLを作成するために十分な情報が記録されていません。このため、サプリメンタルロギングやディクショナリ情報などの付加情報の助けを借りて、意味的に等価な更新伝搬用SQLを作成します。
これは複雑なプロセスです。このため、一般に、作成されたSQLはアプリケーションが実行したSQLと同じSQLにはなりません。
実行した更新SQLがどのようにREDOログファイルに記録されるかを示したのが以下の図です。
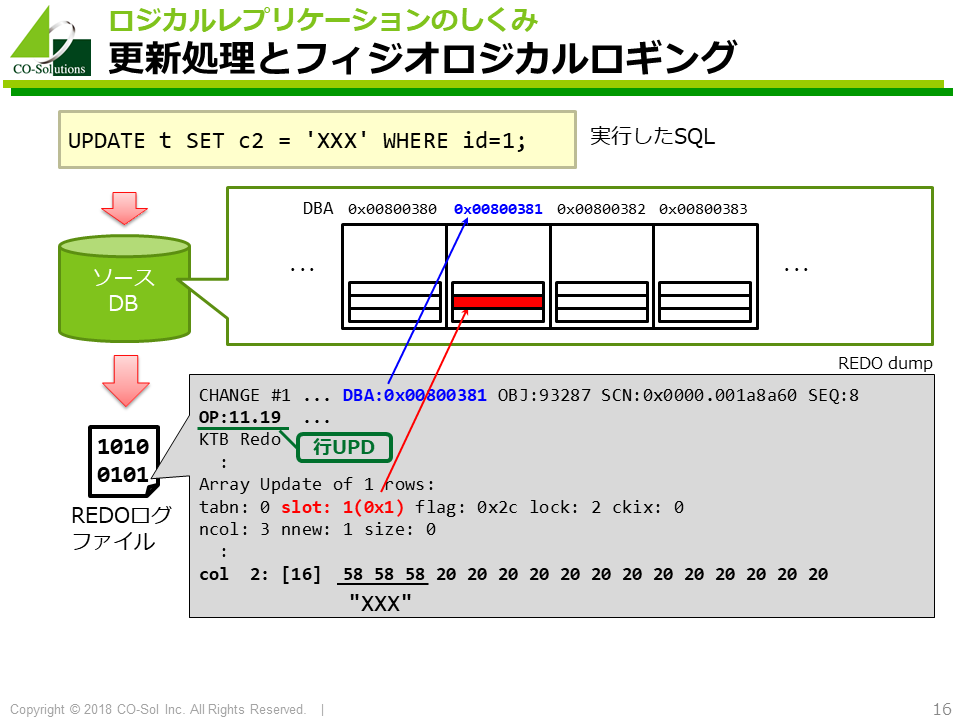
DBA(Data Block Address)に対応するデータブロックにおいて 行UPDATE(Opcode 11.19)という論理的な更新操作の実行を記録していることが分かります。
これがフィジオロジカルロギングの基本的な考え方です。

物理的な側面と論理的な側面の合わせ技で操作を記録(ロギング)しているというわけです。
REDOログファイルには、実行された更新SQLそのものが記録されているわけではありません。 このため、フィジオロジカルロギングで記録された情報を元に更新伝搬用SQLを作成します。 (正確には サプリメンタルロギングやディクショナリ情報などの付加情報も使用します)
フィジオロジカルロギングは、ブロック単位で変更を記録する関係上、 1つの更新SQLを実行した場合でも、内部的には複数の更新として記録することがあります。
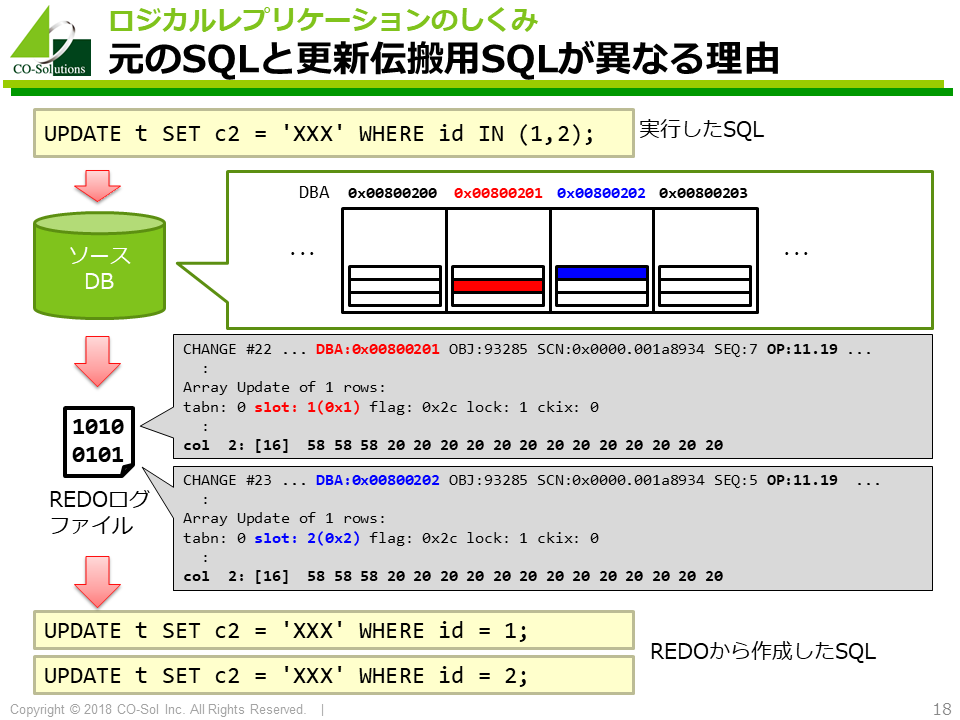
上記の例でも、実行したSQLは1つのUPDATE文ですが、フィジオロジカルロギングでは2つのブロックに対する変更として記録されている様子が確認できます。このため、 フィジオロジカルロギングで記録された情報を元に作成した更新伝搬用SQLは、2つのUPDATE文になります。
このような仕組みのため、更新伝搬用SQLが、実行された更新SQLと異なる場合があります。
更新伝搬用SQLの作成において基礎となるのは、フィジオロジカルロギングによりREDOログファイルに記録された情報ですが、残念ながらこれだけでは更新伝搬用SQLを作成することはできません。
REDOログファイルには
が記録されないためです。

これらの情報がない状態でいわば「無理やり」更新伝搬用SQLを作成すると、作成したSQLは
update "UNKNOWN"."OBJ# 93296"
set "COL 3" = HEXTORAW('58585820202020202020202020202020')
where ROWID = 'AAAWxwAACAAAAIBAAB';のような、意味不明な内部情報を含んだ不完全なモノになってしまいます。
このため、サプリメンタルロギングやディクショナリ情報などの付加情報を使用して、 実際に実行可能である完全なSQLに変換する必要が出てきます。
まず、テーブル名、列名などを管理しているディクショナリを用いて、 名前を正しいものに置き換えます。
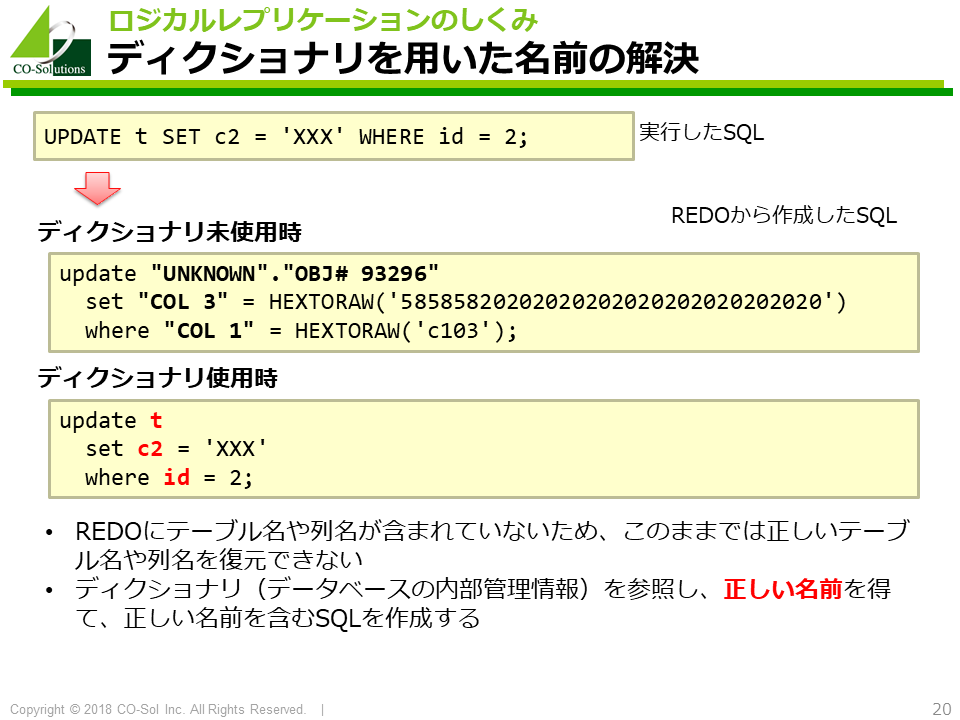
つぎに、サプリメンタルロギングを用いて、物理的な位置情報(ROWID)を論理的な識別子(キー)に置き換えます。

SQLでは、通常、WHERE句にキーを指定することで対象となるデータを特定します。
しかし、REDOには論理的な識別子(いわゆるキー、論理的な位置情報)は含まれておらず、 物理的な位置情報であるROWIDしか含まれていません。 ソースDBでサプリメンタルロギングを有効にすると、論理的な識別子(いわゆるキー)がREDOに含まれるため、検索条件にキーを含めたSQLを作成できるようになります。
サプリメンタルロギングを有効にする方法は以下の通りです。

最小レベルのサプリメンタルロギング(データベースレベル)
ALTER DATABASE ADD SUPPLEMENTAL LOG DATA;識別キーロギング(データベースレベル)
-- 主キー
ALTER DATABASE ADD SUPPLEMENTAL LOG DATA (PRIMARY KEY) COLUMNS;
-- 一意キー
ALTER DATABASE ADD SUPPLEMENTAL LOG DATA (UNIQUE) COLUMNS;
-- 外部キー
ALTER DATABASE ADD SUPPLEMENTAL LOG DATA (FOREIGN KEY) COLUMNS;
-- すべての列
ALTER DATABASE ADD SUPPLEMENTAL LOG DATA (ALL) COLUMNS;以上の処理で更新用のSQL、いわゆるDMLについては更新伝搬用SQLを作成できますが、 DDLについては説明していませんでした。
CREATE TABLE文などのDDLをレプリケーションするのは大変です。 それは、実行したDDLは基本的にREDOログに記録されないためです。 REDOログには、ディクショナリ情報(内部管理情報)の更新が記録されます。

更新伝搬用DDLを作成するには、ディクショナリ情報の更新からDDLを復元するという大変な作業を行う必要があります。ただし、レプリケーション製品によっては、トリガーなどを駆使して実行されたDDLを別途記録しておき、これを元に更新伝搬用DDLを作成する場合もあります。
このように、DDLをレプリケーションするには困難が伴います。 この困難さ故、DDLレプリケーションにはレプリケーション製品ごとに細かい制約があります。 よって、DDLをレプリケーションしたい場合は、使用するレプリケーション製品がどのDDLのレプリケーションに対応しているのか、DDLのレプリケーションに何らかの制約がないか、十分な検討が必要です。
これまで説明したように、ロジカルレプリケーションの鍵となる更新伝搬用SQLの作成は、とても複雑なプロセスです。それゆえ、ロジカルレプリケーションには様々な制約があり、いくつか注意する点があります。

ただし、ロジカルレプリケーションは非常にパワフルなソリューションです。 すでに説明したように、物理レプリケーションでは対応できない、
という利点があります。
ロジカルレプリケーションの利点を享受しつつ、ロジカルレプリケーションの注意点にハマらないためには、使用するロジカルレプリケーション製品について十分な知見を持つベンダに相談することを強くお勧めします。
物理レプリケーションは比較的導入しやすい技術ですが、ロジカルレプリケーションは違います。 この点に注意して導入作業を進めていただければと思います。
お客様に最適なロジカルレプリケーション製品をご案内できるよう、コーソルでは複数のロジカルレプリケーション製品を取り扱っています。
それぞれの製品について、イチオシポイントをご紹介します。
Oracle GoldenGateのイチオシポイントは、 オラクル製品ならではのOracle Databaseとの親和性の高さです。
親和性の高さから、以下の具体的な利点があります。
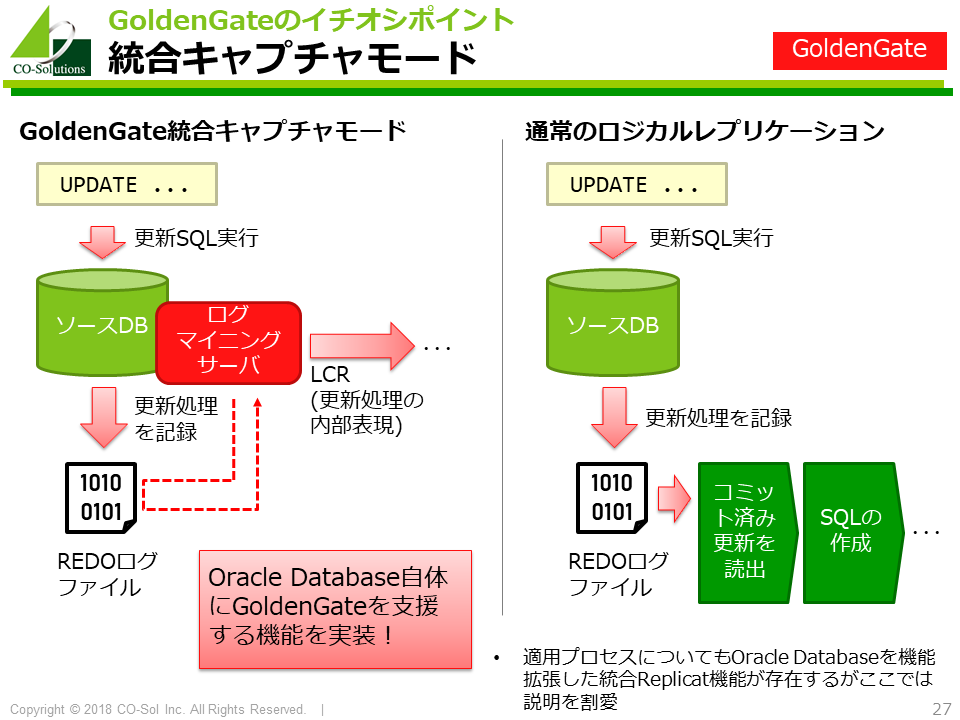
なかでも、統合キャプチャモードは優れた機能で、 Oracle Database自体にGoldenGateを支援する機能を実装しています。
SharePlexのイチオシポイントは、 コミット前伝搬による伝搬遅延の抑止です。
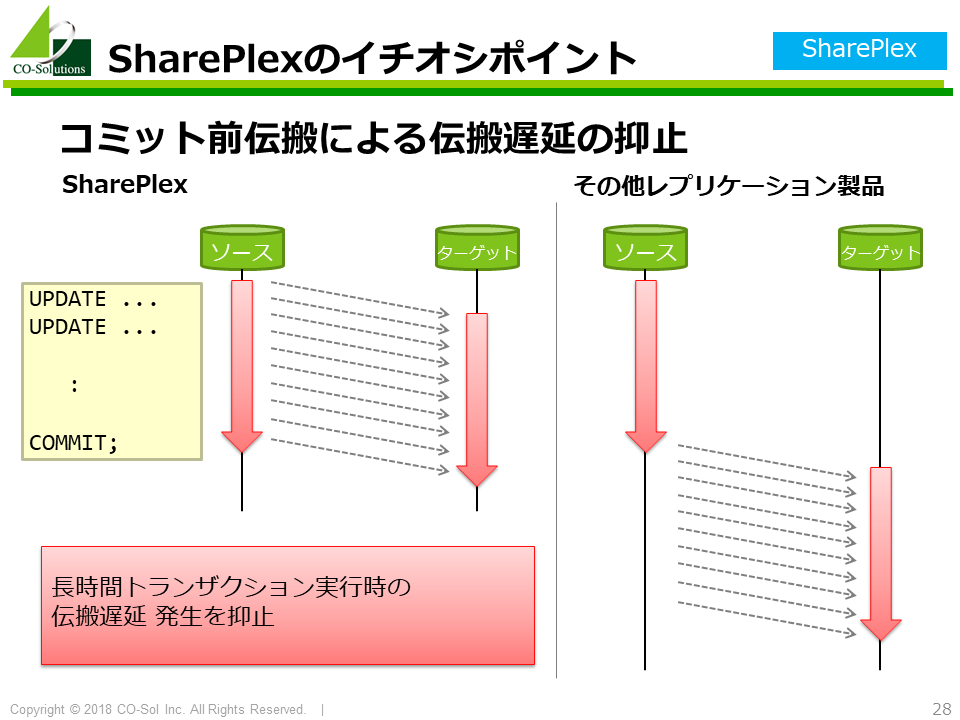
SharePlex以外のレプリケーション製品は、ソースデータベースでコミットが完了した後で、 ターゲットデータベースで更新伝搬用SQLの実行を開始します。 この動作は、大量データのバッチ更新などの長時間トランザクション実行時に問題となります。 ソースデータベースでのコミットを待つ関係上、どうしても伝搬遅延が大きくなるのです。
SharePlexは、ソースデータベースでコミットが完了する前に ターゲットデータベースで更新伝搬用SQLの実行を開始できます。 これにより、長時間トランザクション実行時の伝搬遅延を大幅に小さくすることができます。
SharePlexのコミット前伝搬による伝搬遅延の小ささについては、以下のエントリでも紹介しています。
Qlik Replicate のイチオシポイントは、圧倒的な使いやすさ、導入しやすさ です。具体的には、以下が挙げられます。
Qlik ReplicateのGUIの使いやすさは特筆すべき点があります。
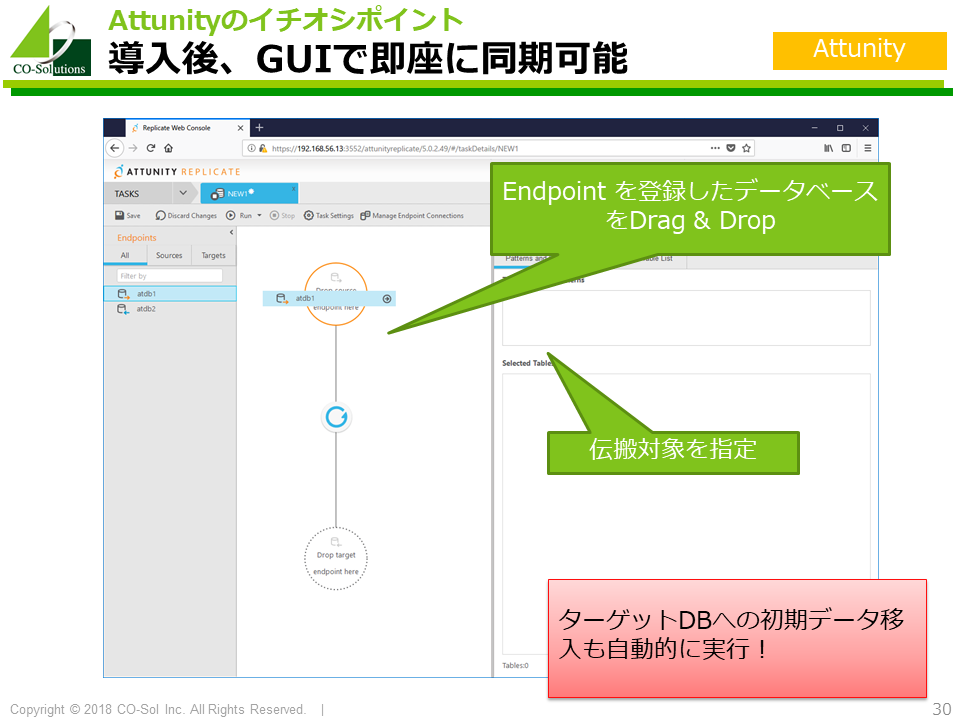
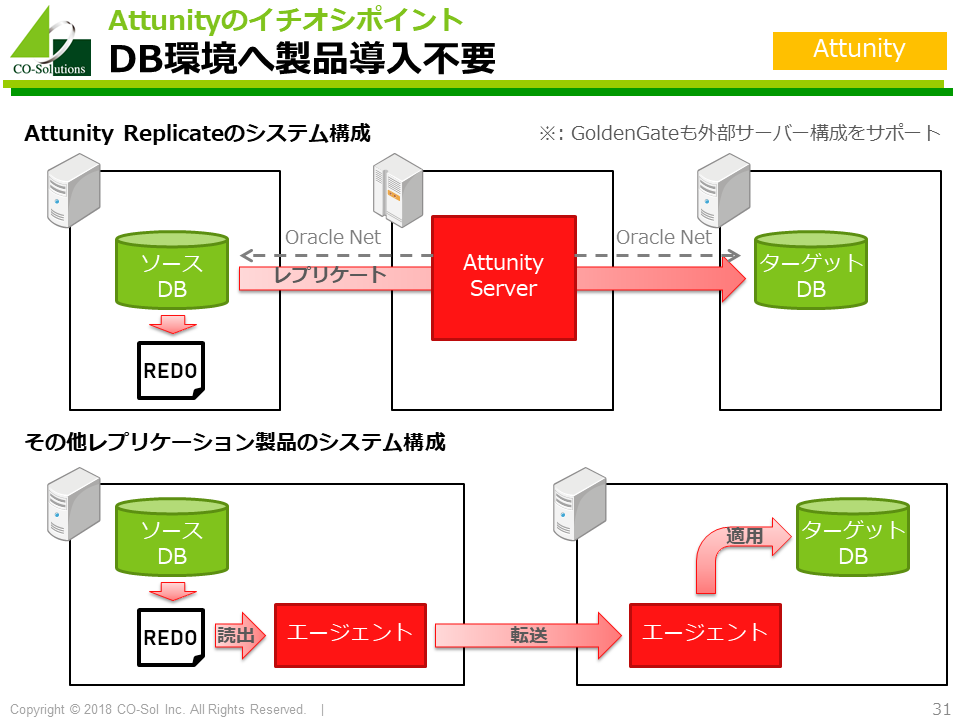
また、ソースデータベースにエージェントをインストールする必要がないため、 既存の環境にできるだけ手を入れたくないお客様にはとても受け入れやすいです。
ロジカルレプリケーションは非常に複雑な技術です。お客様に最適なロジカルレプリケーション製品をご案内できるよう、コーソルでは複数のロジカルレプリケーション製品を取り扱っています。
これらすべての製品について、製品を熟知したエンジニアが設計・導入作業を担います。 Oracleのロジカルレプリケーションをご検討の際はぜひコーソルにお声がけください。



プロフィール
渡部 亮太
・Oracle ACE
・AWS Certified Solutions Architect - Associate
・ORACLE MASTER Platinum Oracle Database 11g, 12c 他多数
カテゴリー
アーカイブ
2026年
2025年
2024年
2023年
2022年
2021年
2020年
2019年
2018年
2017年
2016年
2015年
2014年
2013年
2012年
2000年