技術ブログ
目次
Oracle ACE Proの渡部です。 この記事は、 JPOUG Advent Calendar 2024 の10日目の記事です。 CData Software Advent Calendar 2024 の10日目の記事でもあります。
弊社コーソルは、2024年11月から Change Data Capture技術を用いた論理レプリケーションに対応したデータ連携ツール CData Sync の販売を開始しました。
この記事では、CData Sync を検証する中で見つけた特徴と、その技術的な側面について書きたいと思います。 そして、これと併せて、12月17日開催予定のオンラインセミナーについてもご紹介させていただきます。

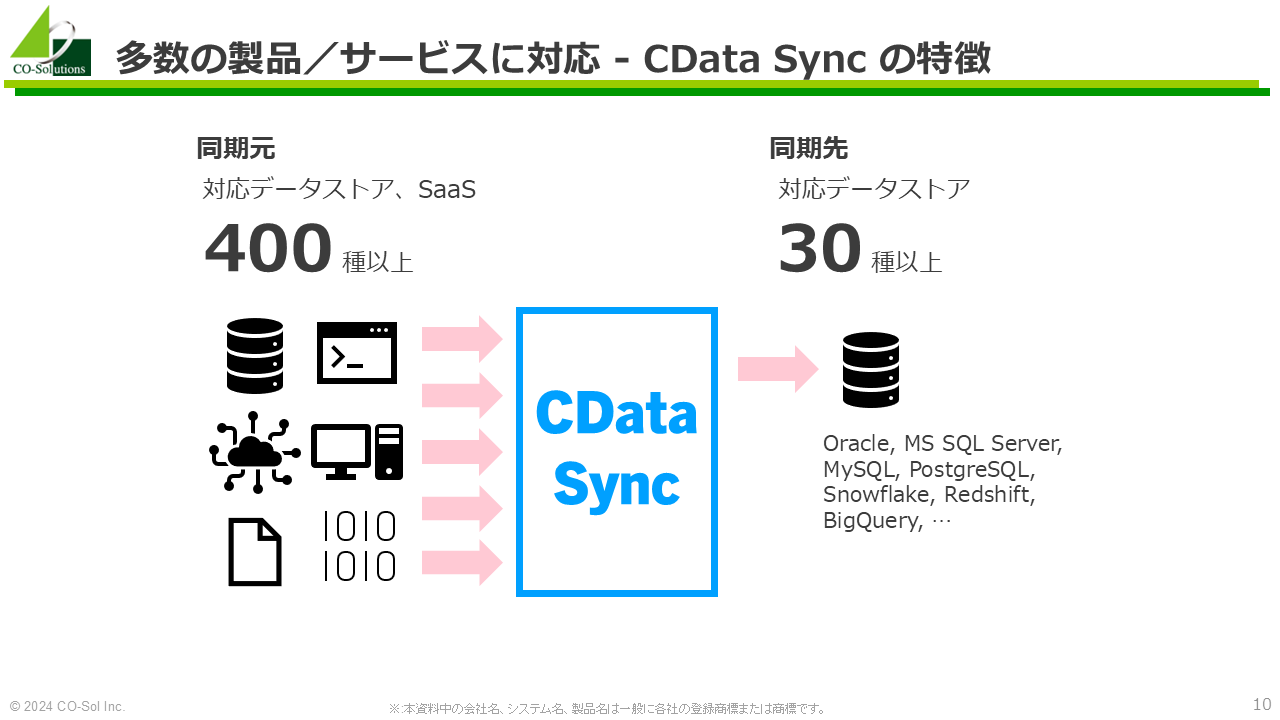
なお、12月17日開催予定の共催セミナーでは、上記の特徴から、いくつかの点を掘り下げて話したいと思っています。
12月17日開催予定の共催セミナーでは、数値的なモノも少し交えながら話そうと思っているのですが、CData Sync を検証して驚いたのは「大量データの差分レプリケーションが高速!」という点です。
これまでもいくつかの論理レプリケーション製品の性能を検証してきましたが、CData Sync の高速さはなかなか凄いです。
エンジニアとしては、驚いているだけではなく、その"高速さ"をもたらしているその技術的な側面を抑えておかないといけません。ということで、SQLトレースを取るなどして色々調べてみましたので、以降ではそれについて書きたいと思います。
なお、以降の説明では、Oracle → Oracle レプリケーション構成を題材とします。 また、LogMinerを用いることを前提とします。
(一応の補足: CData Sync は Oracle → Oracle以外のレプリケーション構成にも対応しています。異機種RDBMS間のレプリケーション構成にも対応しています。)
CData Sync のレプリケーションに関わる論理アーキテクチャは以下のとおりです。
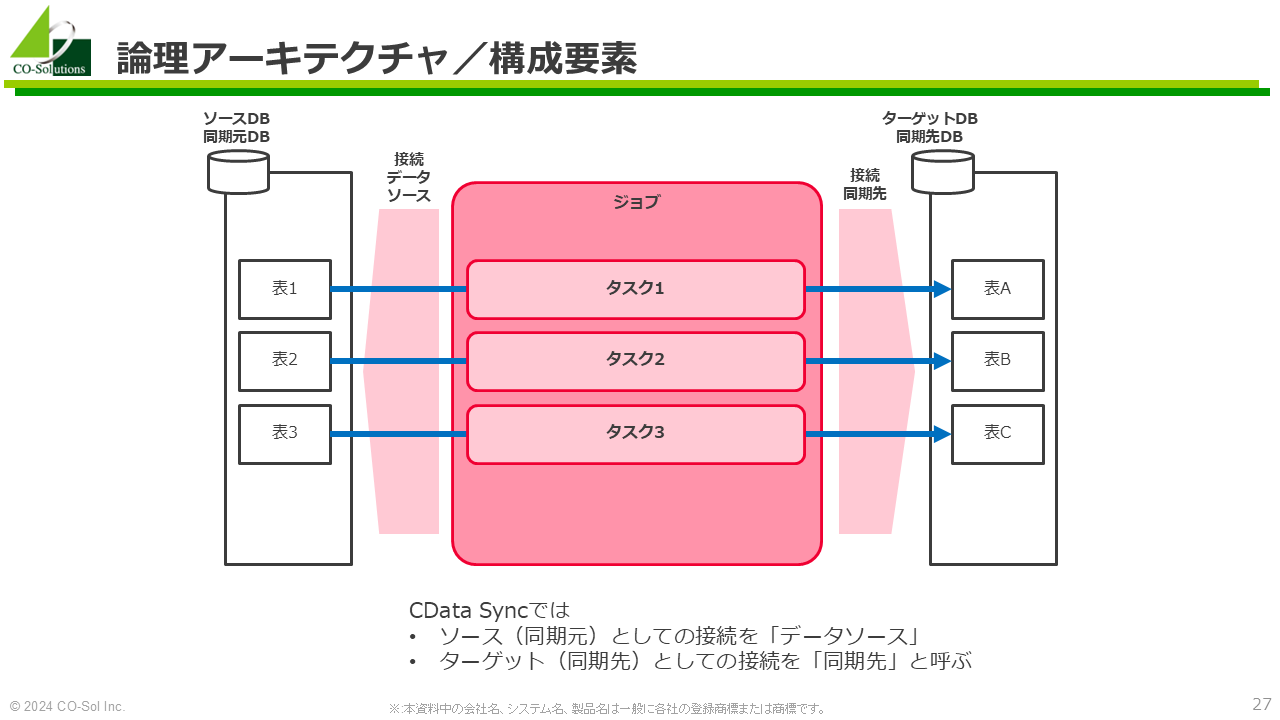
CDCタイプのジョブは、LogMinerなどの機能を用いて、ソースDBMSから変更内容を取得し、差分レプリケーションを実現します。
CDCタイプのジョブは、初回と2回目以降で処理内容が異なります。

初回ジョブ実行におけるデータ処理の仕組みは比較的シンプルで以下のようになっています。
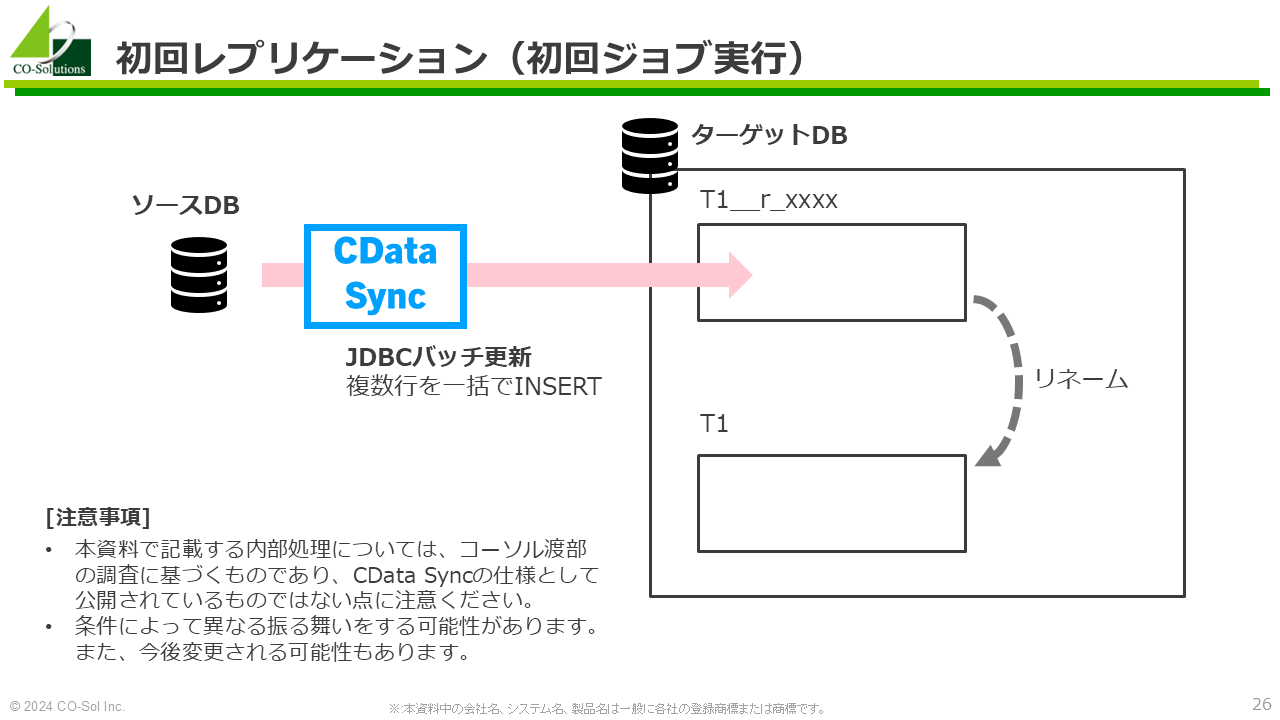
これにより、全件レプリケーションを実現しています。
初回ジョブ実行におけるポイントは、JDBCバッチ更新を用いて複数行を一括でINSERTしている点なのですが、この機能は2回目以降ジョブ実行でも使用しているため、そこで説明します。
なお、スライドにも記載していますが、この記事で記載した内部処理は、コーソル渡部の調査に基づくものであり、CData Syncの仕様として公開されているものではありません。条件によって異なる振る舞いをする可能性があります。また、今後変更される可能性もありますので、ご注意ください。
2回目以降のジョブ実行におけるデータ処理の仕組みは以下のようになっています。
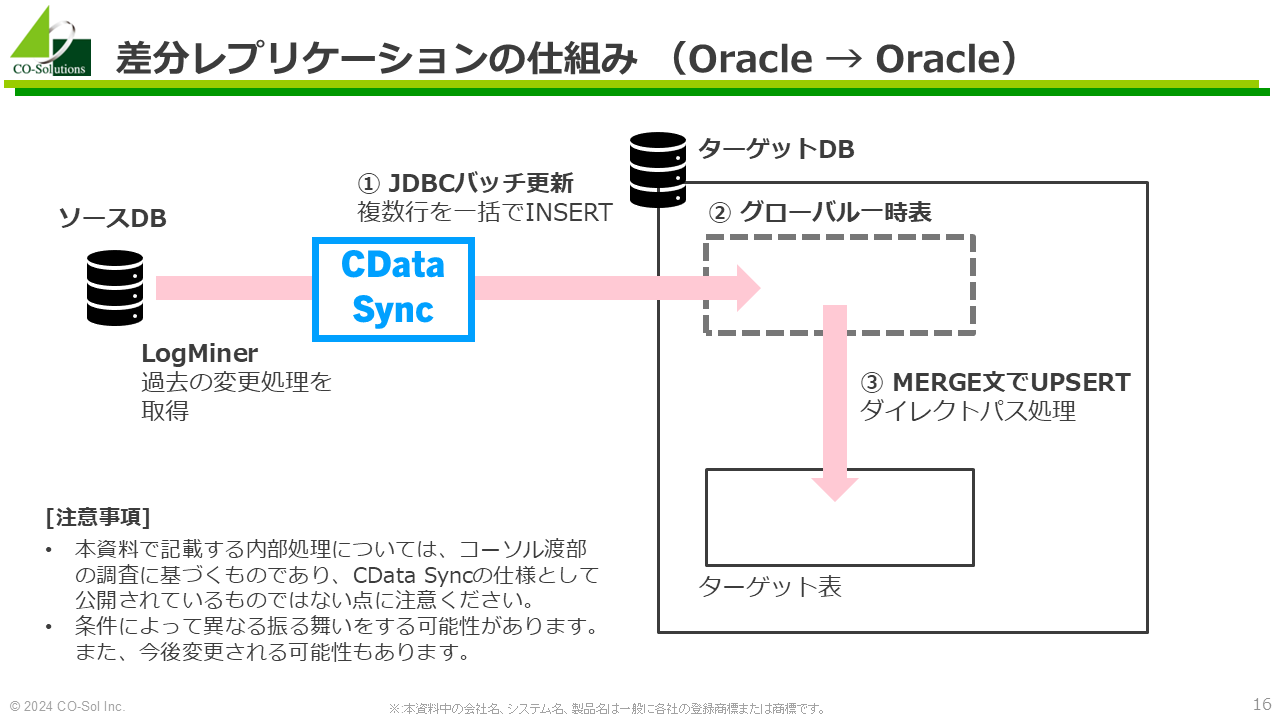
これにより、差分レプリケーションを実現しています。

JDBCバッチ更新は、同一DMLの複数回実行をまとめることができる機能です。 複数回実行を1つにまとめることで、アプリケーション~DBサーバのネットワーク ラウンドトリップの回数を減らして、パフォーマンスの向上を図ることができます。
初回および2回目以降のジョブ実行では、JDBCバッチ更新を用いて複数行のINSERT処理を高速化しています。
該当処理のSQLトレース(tkprof加工済み)を以下に示します。
INSERT INTO "U1"."U1_T1__r_200468282" ("_cdatasync_deleted", "PK", "S") VALUES (:1 , :2 , :3 )
call count cpu elapsed disk query current rows
------- ------ -------- ---------- ---------- ---------- ---------- ----------
Parse 1 0.00 0.00 0 0 0 0
Execute 43 1.05 1.10 0 13089 129402 42086
Fetch 0 0.00 0.00 0 0 0 0
------- ------ -------- ---------- ---------- ---------- ---------- ----------
total 44 1.05 1.10 0 13089 129402 42086
:
Rows (1st) Rows (avg) Rows (max) Row Source Operation
---------- ---------- ---------- ---------------------------------------------------
0 0 0 LOAD TABLE CONVENTIONAL U1_T1__r_200468282 (cr=988 pr=0 pw=0 time=31886 us starts=1)
Elapsed times include waiting on following events:
Event waited on Times Max. Wait Total Waited
---------------------------------------- Waited ---------- ------------
SQL*Net more data from client 10343 0.00 0.09
Disk file operations I/O 1 0.00 0.00
log file sync 1 0.02 0.02
SQL*Net message to client 43 0.00 0.00
SQL*Net message from client 43 0.43 3.58以下が分かります。
JDBCバッチ更新でデータがINSERTされるのは一時表(グローバル一時表)です。 ターゲット表を直接更新するのではなく、まず一時表にデータがINSERTしてから、データをターゲット表に反映する動きとなります。
一時表はデータを一時的に保持するための特殊な表です。 REDOを生成しないので高速に処理できます。また、データの保持期間は一時的なのですが、通常の表と同じようなデータ処理が可能です。 CData Syncはこの利点を生かして、一時表 → 永続表 のダイレクトパスロードを実行しています。
一時表へのINSERTが完了したら、MERGE文を用いてターゲット表に対するUPSERT処理を実行します。MERGE文には /*+ APPEND */ヒントを付与して、ダイレクトパス処理を試みます。

UPSERT処理とは、
する処理の通称です。UPSERT処理により、いわゆる「差分更新」を実現できます。 OracleではMERGE文でUPSERT処理を実行できます。
また、MERGE文に /*+ APPEND */ヒントを付与しているため、可能な場合は、ダイレクトパス処理で実行されます。具体的には、既存の行がないと、INSERTがダイレクトパス処理で実行されます。
ご存じの方も多いかと思いますが、DMLにおいて、ダイレクトパス処理の高速化効果は"絶大"です。 この記事で、具体的数値とともにその効果の大きさを書きたいところですが… 俗にいう"ベンチマーク条項(DeWitt条項)"があるため、具体的な数値を書くことを躊躇してしまいます(他社製品との性能比較を嫌う条項だと思うので、オラクルさんから怒られることはないとは思うのですが、一応・・・)。
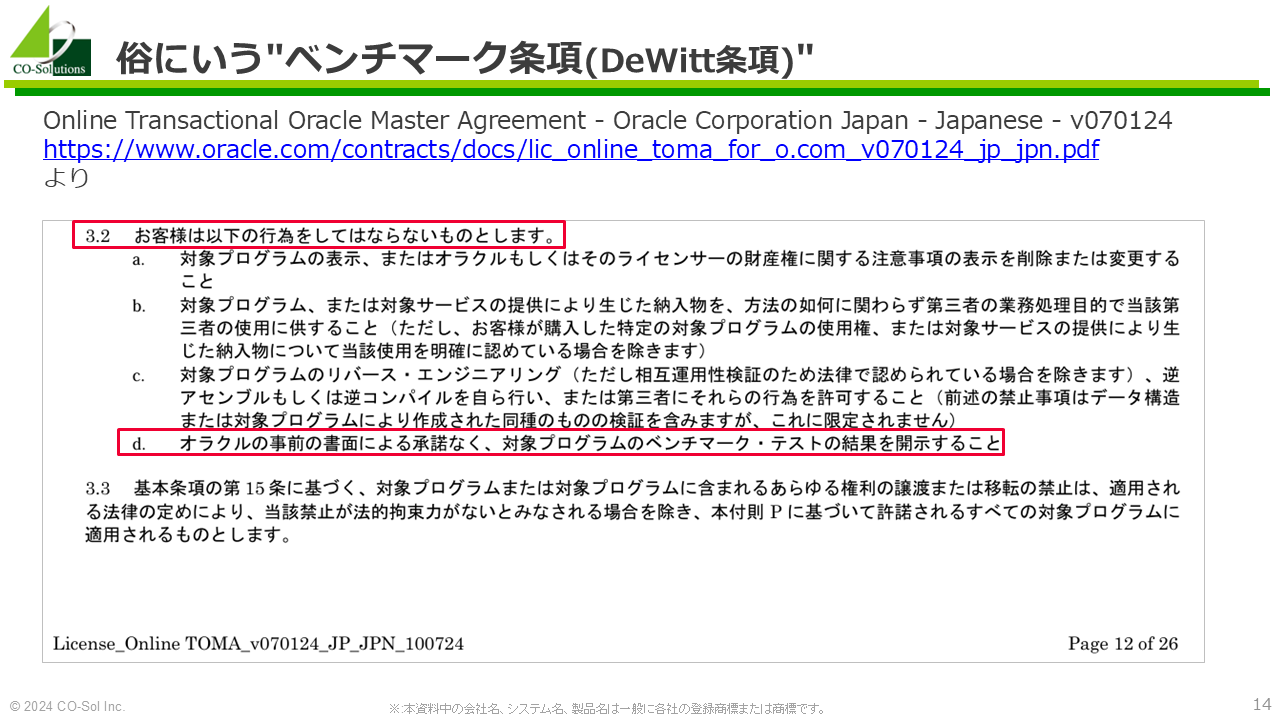
ここでは、「ダイレクトパス処理と通常の処理(非ダイレクトパス処理)で10倍以上の差があった」という記載にとどめておきます。
12月17日開催予定のオンラインセミナーでは、もう少し具体的な数値をこっそり(というものでもないですが)お話ししたいと思っています。お時間に都合がつけば、是非ご参加くださいませ。
大量データの差分レプリケーションの高速さを実現している技術的な側面を理解したとき、私はいくつかの感想を抱きました。雑感気味でまとまりがないですが、書いておきます。
私がこれまで触ってきた論理レプリケーション製品は、「ソースDBのトランザクション実行をターゲットDBで再現する」ことを目標にしている印象があります。 この感覚からすると、CData Syncの思い切りの良さは新鮮でした。
12月17日にCData社様と共催でオンラインセミナーを開催します。本記事で触れた性能関係を含めたいくつかのCData Syncの長所についてお話ししますので、お時間に都合がつけば、是非ご参加くださいませ。
セッション構成
JPOUG Advent Calendar 2024 の明日11日目の記事は、wmo6hashさんに執筆いただく予定です。wmo6hashさん、よろしくお願いいたします!



プロフィール
渡部 亮太
・Oracle ACE
・AWS Certified Solutions Architect - Associate
・ORACLE MASTER Platinum Oracle Database 11g, 12c 他多数
カテゴリー
アーカイブ
2026年
2025年
2024年
2023年
2022年
2021年
2020年
2019年
2018年
2017年
2016年
2015年
2014年
2013年
2012年
2000年