Oracle SQLチューニングの基本は実行計画を理解することです。実行計画はツリー構造で、様々なオペレーションから構成されます。
この記事では、INDEX FAST FULL SCANオペレーションについて説明します。
INDEX FAST FULL SCANオペレーションとはどのようなオペレーションか?
クエリで参照する列がすべて索引に含まれる場合、索引だけを読取る実行計画が選択されたとき、索引へのアクセスに使用されるオペレーションです。
クエリで参照する列がすべて索引に含まれる場合、すなわち、クエリで参照する列が、その索引の索引列すべて含まれる場合、必要なデータを索引だけから得ることができます。一般に、索引は表よりもサイズは大幅に小さいですから、索引にだけアクセスすることで性能を大幅に向上できます。
また、INDEX FAST FULL SCANオペレーションでは、表のフルスキャン(TABLE ACCESS FULL)と同様にマルチブロックリードでブロックを読み出しますので、この点からも性能の向上を見込めます。
実行計画の例と処理イメージ図
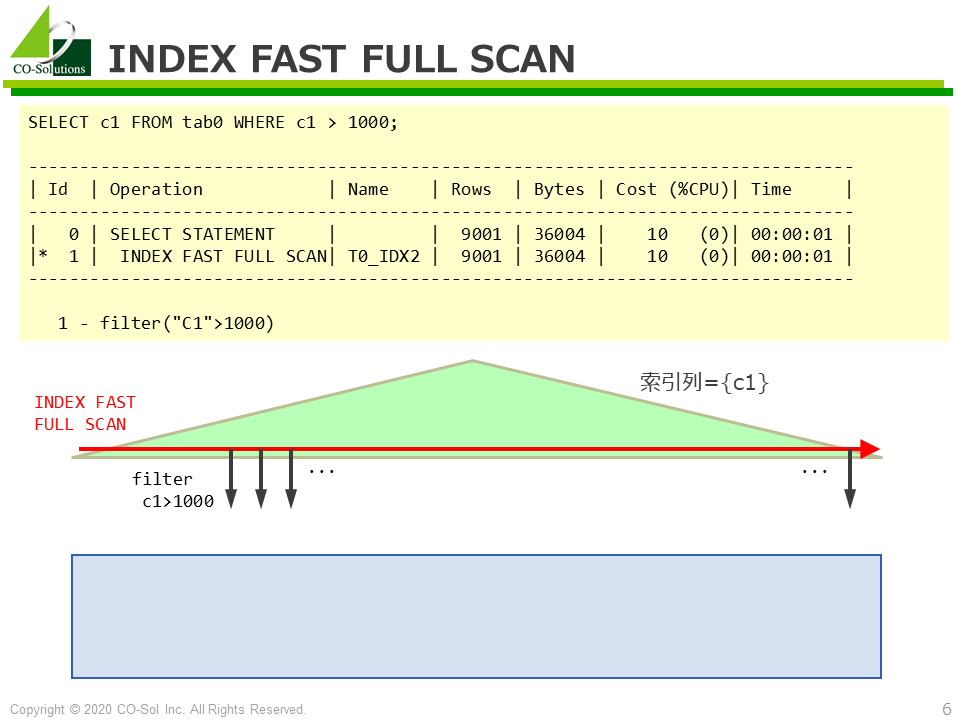
SELECT c1 FROM tab0 WHERE c1 > 1000;
--------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 9001 | 36004 | 10 (0)| 00:00:01 |
|* 1 | INDEX FAST FULL SCAN| T0_IDX2 | 9001 | 36004 | 10 (0)| 00:00:01 |
--------------------------------------------------------------------------------
1 - filter("C1">1000)INDEX FAST FULL SCANオペレーションに関するFAQ
INDEX FAST FULL SCANオペレーションが使われる条件には何がありますか?
以下の条件を満たす必要があります。
- 問合せで参照している全ての列が、対象索引の索引列に含まれること
- 索引列の少なくとも一つの列にNOT NULL制約が設定されていること
条件の2.について補足します。
索引列の値がNULLである行は、索引には含まれません。索引列が複数列である場合を含めて、より正確に表現すると、索引列である、すべての列について、値がNULLである行は索引に含まれません。
索引に含まれない行があるということは、索引から行のデータを得られないということになりますから、INDEX FAST FULL SCANオペレーションを使う実行計画の目的である、「索引のみからデータを得る」ことができなくなります。
このため、条件の2.が満たされていない場合、すなわち、索引列のすべての列にNOT NULL制約が設定されていない場合、INDEX FAST FULL SCANオペレーションを使う実行計画は選択されません。
INDEX FAST FULL SCANオペレーションを使う実行計画は望ましくないですか?
一般に、INDEX FAST FULL SCANオペレーションを用いた全行データの読み出しは、表のフルスキャン(TABLE ACCESS FULLオペレーション)を用いた全行データの読出しよりも処理が高速です。よって、INDEX FAST FULL SCANオペレーションを使う実行計画は通常、最適です。
INDEX FAST FULL SCANオペレーションを使う実行計画に誘導するヒントは何ですか?
INDEX_FFSヒントです。以下にINDEX_FFSヒントを指定したSELECT文の例を示します。
-- 特定の索引を使用したINDEX FAST FULL SCANを指示する場合
SELECT /*+ INDEX_FFS(<TABLE_NAME> <INDEX_NAME>) */ FROM ...
-- 索引を使用したINDEX FAST FULL SCANを指示し、どの索引を使用するかは指示しない場合
SELECT /*+ INDEX_FFS(<TABLE_NAME>) */ FROM ...INDEX_FFSヒントを指定してもINDEX FAST FULL SCANオペレーションが使用されません
先に説明した、INDEX FAST FULL SCANオペレーションが使われる条件を満たしていない場合があります。特に索引列へのNOT NULL制約については気づきにくいため注意が必要です。
以下の例では、索引列のNOT NULL制約を外しています。INDEX FAST FULL SCANオペレーションではなく、TABLE ACCESS FULLオペレーションが使用されていることが分かります。
SQL> ALTER TABLE tab0 MODIFY c1 NULL;
:
SQL> SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY);
--------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 10000 | 40000 | 907 (1)| 00:00:01 |
| 1 | TABLE ACCESS FULL| TAB0 | 10000 | 40000 | 907 (1)| 00:00:01 |
--------------------------------------------------------------------------INDEX FAST FULL SCANオペレーションの実行時、ブロックは1ブロックずつよみだされますか?
いいえ。索引のブロックは複数ブロックまとめて読みだされます(マルチブロックリード)。これにより、大量のブロックの読み出し処理の高速化を図っています。
参考情報
キーワード
索引アクセス INDEX UNIQUE SCAN INDEX FAST FULL SCAN 索引レンジ・スキャン

