主要RDBMS製品の比較 – 文字コード, 文字セット, 照合順序
Oracle ACE Proの渡部です。
主要なRDBMS製品を比較します。
- 大枠を整理することが最大の目的です。細かい例外事項や拡張機能は適宜記載を割愛しています。
- 2022年9月時点の最新バージョンをベースに記載していますが、記載内容にバージョン依存は少ないはずです。
- 時間ができた時に随時追記予定です。
- もし誤りを見つけた場合は、優しく教えていただけると嬉しいです。→ https://twitter.com/wrcsus4 or ryota.watabe at cosol dot jp
「主要RDBMS製品の比較」ページ一覧
- アーキテクチャ, スキーマ, データベース, メモリ
https://cosol.jp/techdb/2022/09/rdbms_architecture_comparison/
- 記憶域, トランザクションログ, 物理構造
https://cosol.jp/techdb/2022/09/rdbms_compare_storage/
- バックアップ, 災害対策構成, 論理レプリケーション
https://cosol.jp/techdb/2022/09/rdbms_compare_bk_dr_rep/
- 同時実行制御, トランザクション分離レベル
https://cosol.jp/techdb/2022/09/rdbms_compare_conc_cntl_transaction/
- 文字コード, 文字セット, 照合順序
https://cosol.jp/techdb/2022/09/rdbms_compare_charcode/
- 接続, ユーザー, コマンドラインクライアント
https://cosol.jp/techdb/2022/09/rdbms_compare_conn_user/
立場の表明
- コーソルはデータベース関連製品の販売およびプロフェッショナルサービス提供を行っている営利企業です。
- https://cosol.jp にある全てのコンテンツは、情報提供に加えて、コーソルの認知度向上、コーソルの営利活動の促進を目的としています。


著者について

RDBMS製品における文字コードと本記事の対象
コンピュータで文字を取り扱うには文字コードの適切な理解および使用が必要です。
RDBMS製品において、文字コードにおける重要な論点は以下の2つです。
- (A) データ格納用文字コード : 文字データをデータベースに格納するときに、どの文字コードを用いて格納するか
- (B) クライアント実行環境用文字コード : クライアントが、文字データをデータベースに格納したり、データベースから参照したりするときに、どの文字コードの元で取り扱うか
- (B) が必要な理由は、プラットフォーム毎に対応している文字コード体系が異なるためです。たとえば、Windowsのコマンドプロンプトでは一般にシフトJISが使用されるため、(A) がUTF-8の場合でも、クライアント実行環境に合わせてシフトJISを設定する必要があります。

本記事では、(A) データ格納用文字コードについて記載します。
なお、(A), (B) 以外にも文字コードを考慮すべき点として以下がありますが、これらも本記事の記載対象外とします。
- オブジェクト名の文字コード
- ストアドプロシージャのソースコードの文字コード
- ファイルシステムにおけるファイル名の文字コード
- ファイルシステムにおけるファイルに含まれるデータの文字コード
文字セットと照合順序
データベースに格納した文字データの取り扱いにおいては、文字セットと照合順序が重要です。
(a) 文字セット
- データベースに格納できる文字の集合を定義したもの
- 逆にいうと、文字セットに含まれない文字は、データベースに格納できない
- 一般的に使用される、いわゆる「文字コード」に準ずる形で定義される
- 例) OracleのJA16SJISは、シフトJISをベースに定義されている
- 多くの場合、エンコーディングとともに定義される
- エンコーディング:ある文字にどのバイナリ値を割り当てるかのルール
- 例) シフトJISでは「あ」= 0x82A0
(b) 照合順序
- 文字データの等値判定およびソート(比較)のルール
- 等値判定: どの文字とどの文字を「同じ」と判定するか
- 比較(ソート) : 文字同士の大小関係(並び順)をどうするか
- バイナリ比較と非バイナリ比較(言語比較)に大別される
- バイナリ比較: 非常にシンプル。文字のバイナリ値を元に、等値判定および比較(ソート)が行われる
- 非バイナリ比較(言語比較): 言語的な観点を加味して、等値判定および比較(ソート)の動作が定義される
- 例) 大文字小文字の区別、濁点半濁点の区別、アクセント記号の区別など
文字セットの設定/設定対象
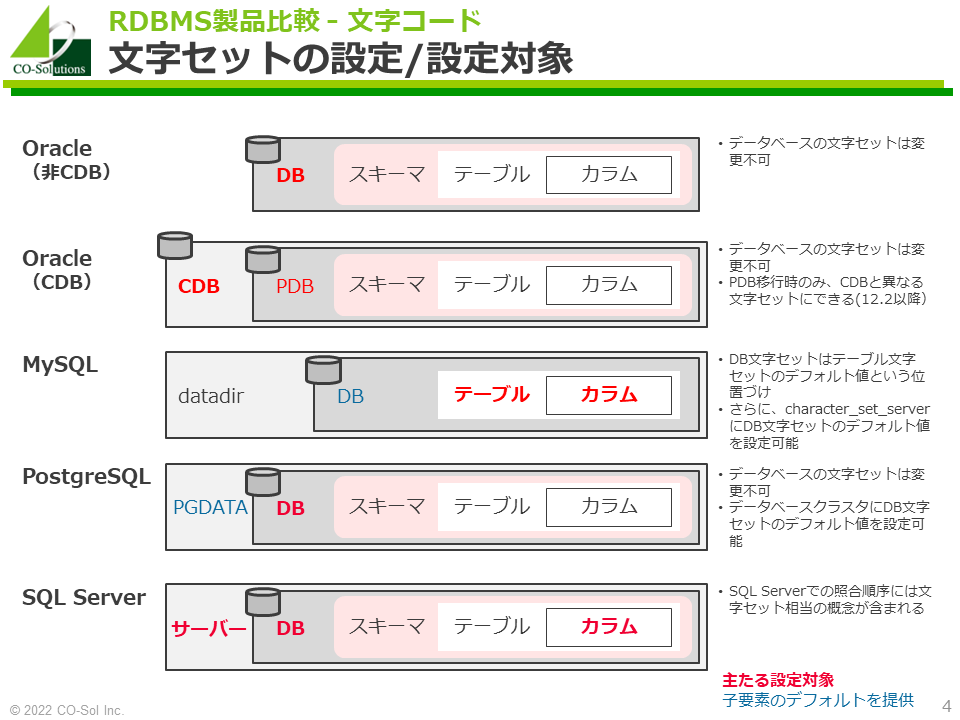
Oracle
- 基本的にデータベース単位で文字セットを指定します。したがって、あるデータベースにおいて異なる複数の文字セットを使用することはできません。
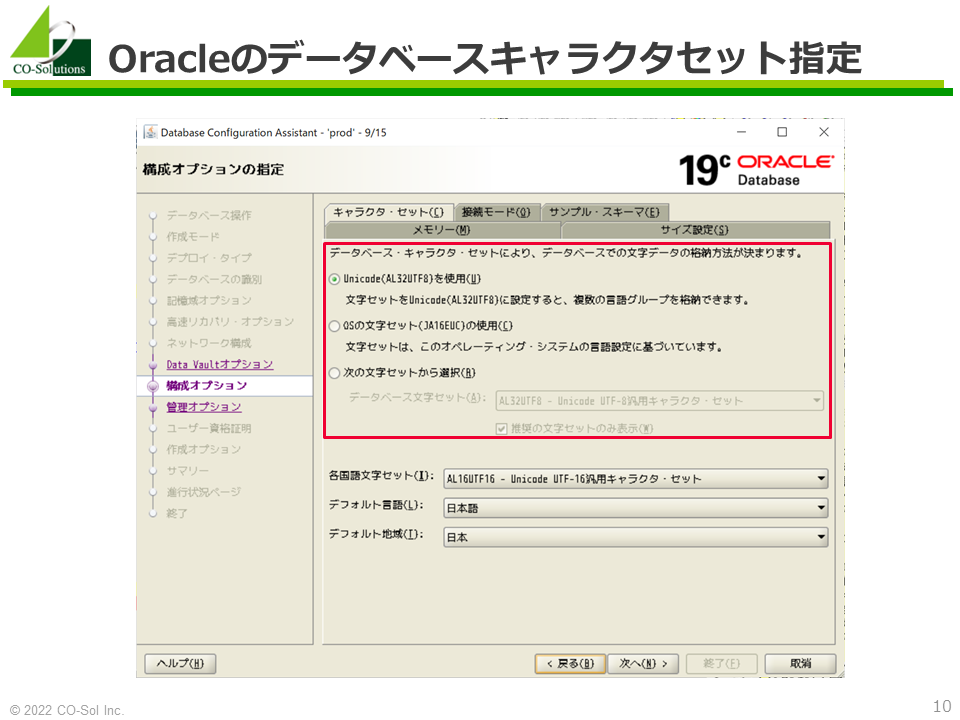
- データベース作成時にデータベースの文字セット(データベースキャラクタセット)を指定します。
- データベース作成後、データベースの文字セット(データベースキャラクタセット)は変更できません。
- 厳密には上位互換のデータベースキャラクタセットには変更できますが、実務的に使用できるケースは極めて少ないです。
- CDB構成でも、原則的にCDBとPDBで同じ文字セットを指定する必要があります。ただし、既存のPDBを移行した場合は、CDBとPDBで異なる文字セットにできます。
- ほとんど使用されないため、各国語キャラクタセット(NCHAR, NVARCHAR2)は説明の対象外とします。
MySQL
- テーブルおよびカラムに対して、任意の文字セットを指定できます。したがって、あるデータベース、あるテーブルにおいて、異なる複数の文字セットを使用できます。
- インスタンスおよびデータベースに対して、デフォルトの文字セットを指定できます。データベースおよびテーブル作成時に文字セットの指定を省略した場合、デフォルトの文字セットが適用されます。
PostgreSQL
- データベース単位で文字セットを指定します。したがって、あるデータベースにおいて異なる複数の文字セットを使用することはできません。
- データベースクラスタ(PGDATA)に対して、デフォルトの文字セットを指定できます。データベースに文字セットの指定を省略した場合、デフォルトの文字セットが適用されます。
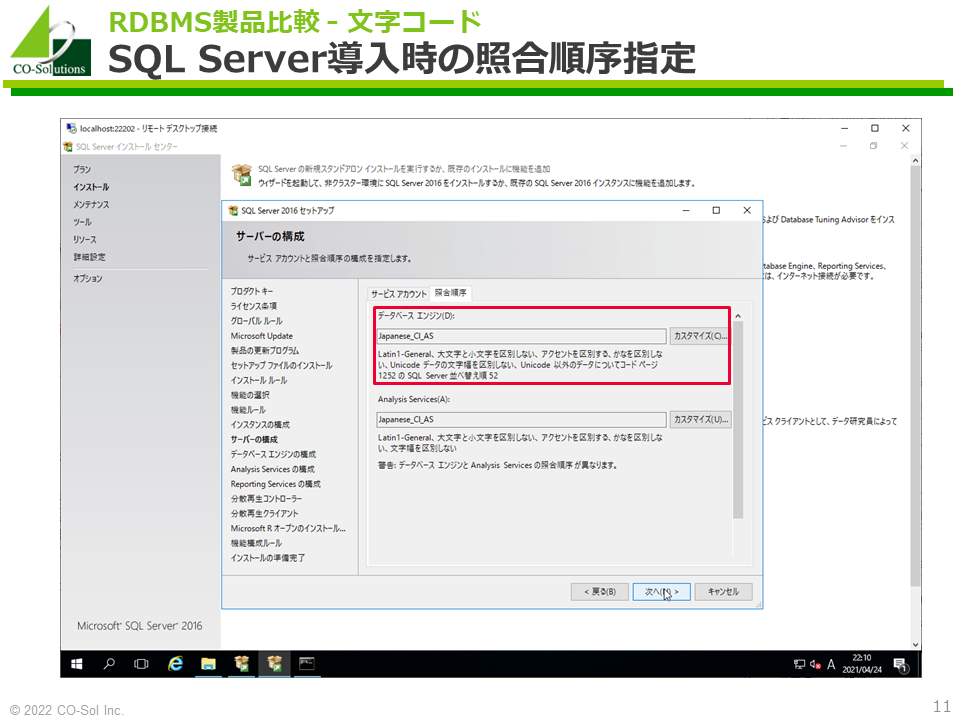
SQL Server
- サーバー、データベース、カラムに文字セットを指定できます。
- ただし、SQL Serverでは、文字セットと照合順序を合わせたものを「照合順序」と呼ぶため、実際に設定する項目は「照合順序」です。紛らわしいため注意してください。
- インストール時にサーバーの「照合順序」(= (a) 文字セット+ (b) 照合順序)を指定します。
日本語環境で使用される主な文字セット
日本語環境で使用される主な文字セットをまとめます。
それぞれの文字セットは、シフトJIS、日本語EUC、Unicodeのいずれかをベースにしていますが、ベンダー定義文字の有無や最新規格の対応などの細かい部分で違いがあります。
Oracle
- JA16SJIS : シフトJIS相当。JIS X 0208およびWindows-31J由来のベンダー定義文字をサポート
- JA16SJISTILDE : シフトJIS相当。JIS X 0208およびWindows-31J由来のベンダー定義文字をサポート。チルダ文字化け問題に対処
- JA16EUC : 日本語EUC相当。JIS X 0208およびJIS X 0212-1997 (補助漢字)をサポート。
- JA16EUCTILDE : 日本語EUC相当。JIS X 0208およびJIS X 0212-1997 (補助漢字)をサポート。チルダ文字化け問題に対処
- AL32UTF8 : Unicode UTF-8相当。
- AL16UTF16 : Unicode UTF-16相当。使用できるデータ型に制限あり(NCHAR型、NVARCHAR2型)。
チルダ文字化け問題については、以下の記事を参照してください。
MySQL
- cp932 : シフトJIS相当。JIS X 0208およびNEC特殊文字、IBM拡張文字をサポート
- sjis : シフトJIS相当。JIS X 0208をサポート(NEC特殊文字、IBM拡張文字をサポートしない)
- eucjpms : 日本語EUC相当。JIS X 0208およびNEC特殊文字、IBM拡張文字をサポート
- ujis : 日本語EUC相当。JIS X 0208をサポート(NEC特殊文字、IBM拡張文字をサポートしない)
- utf8mb4 : Unicode UTF-8相当。BMPおよび非BMPをサポート
- utf8 : Unicode UTF-8相当。BMPをサポート(非BMPをサポートしない)
注意点
- Unicodeベースの文字セットとしては、一般にutf8ではなくutf8mb4を使用すべきです。
- utf8は非BMPをサポートしていないのみならず、今後の機能拡張も期待できません。
PostgreSQL
- UTF8 : Unicodeがベース。エンコーディングはUTF-8
- EUC_JP : 日本語EUC相当。JIS X 0208をサポート
- EUC_JIS_2004 : 日本語EUC相当。JIS X 0213をサポート
注意点
- 「(A) データ格納用文字コード」(サーバキャラクタセット)として、シフトJIS系の文字コードをサポートしません。
- 「(B) クライアント実行環境用文字コード」ではシフトJIS系の文字コードをサポートします。
SQL Server
- Japanese... : シフトJIS相当。JIS X 0208およびWindows-31J由来のベンダー定義文字をサポート
- Japanese_CI_AS : 上記の特徴+大文字小文字を区別しない(Case Insensitive) + アクセント記号を区別する(Accent Sensitive)
- など
- Japanese..._UTF8 : Unicode UTF-8相当。SQL Server 2019以降で使用可能。
注意点
- 上記の"..."においては、大文字小文字の区別、アクセント記号の区別など、主に (b) 照合順序 に関係するオプションを指定します。
- SQL Serverでは「照合順序」を、上記の (a) 文字セットと (b) 照合順序 の両方を包含した統合的な概念として使用します。
たとえば、SQL Serverの「照合順序」"Japanese_CI_AS"は以下の意味を持ちます。
- (a) 文字セット : "Japanese" → シフトJIS相当(日本語Windowsでの標準的な文字コード)
- (b) 照合順序 : "_CI_AS" → 大文字小文字を区別しない(Case insensitive) + アクセント記号を区別する(Accent Sensitive)
- 「(A) データ格納用文字コード」として、日本語EUC系の文字コードをサポートしません。
- UTF-8は、SQL Server 2019以降で使用可能です。
- UTF-16であれば、SQL Server 2019より前で使用可能。ただし、NCHAR, NVARCHAR型を使用する必要があります。また、追加面(非BMP) を使用する場合は、「照合順序」に"_SC"の指定が必要です。
文字セットのUnicode対応
過去の制約が特にない場合、基本的にUnicode(UTF-8)をベースにした文字コード(文字セット)を使用することになるはずです。
Unicodeを使用することで以下の利点が得られます。
- グローバルのデファクトスタンダードに乗ることができる。言い換えると、日本ローカル故の問題点を回避できる
- 顔文字(絵文字、Emoticon)など様々な文字を使用できる
- 多言語対応
Unicodeを使用するにあたっての留意点は以下です。
- 文字セットが追加面(非BMP)に対応しているか
- 顔文字、JIS X 0213の一部などが追加面に含まれます。
- どのエンコーディングを使用するか。ただし、基本的にはUTF-8を使用することになるはずです。
- 新しいUnicodeバージョンへ対応しているか。必ずしも最新である必要はないですが、顔文字(Emoticons)など、広く一般に必要とされる機能に対応したバージョンであることが望ましいです。
Oracle
MySQL
- 原則的に "utf8mb4"を使用します。
- "utf8"は追加面(非BMP)に対応していません。
PostgreSQL
- 原則的に "UTF8"を使用します。
- 内部的にOSのロケールを使用しているため、動作の詳細はOS側(libc)に準じます。
SQL Server
- SQL Server 2019以降では、"_UTF8"を指定した照合順序を使用することで使用可能になります。
- 日本語環境におけるデフォルトの照合順序は "Japanase_CI_AS"で、UTF8サフィックスがついておらず、Unicode非対応なことに注意してください。Japanase_CI_ASの代りに、"Japanase_CI_AS_UTF8"などの、"_UTF8"サフィックスがついた照合順序を使用すれば、Unicodeに対応できます。
- SQL Server 2019より前でも、NCHAR, NVARCHAR型を使えばUnicodeを使用できます。
- エンコーディングはUTF-16です。
- ただし、追加面(非BMP) を使用する場合は、"_SC"サフィックスがついた照合順序を使用する必要があります。
照合順序の注意点
照合順序は、以下に関する文字データの取扱いルールです。
- 等値判定: どの文字とどの文字を「同じ」と判定するか
- 比較(ソート) : 文字同士の大小関係(並び順)をどうするか
等値判定およびソートのルールを要件に応じて使い分けられるように、DB製品にはいくつかの照合順序があらかじめ用意されています。
逆に言うと、要件に合致した等値判定およびソートの動作になるように、適切な照合順序を選ぶ必要があります。
適切な照合順序を選択しないと、意図に反した等値判定およびソートの動作になりえます。また、
インデックスの使用可否、結合操作などにも影響します。
照合順序はバイナリ比較(バイナリ値で比較)と非バイナリ比較(言語比較)に大別できます。
- バイナリ比較 : 非常にシンプル。文字のバイナリ値を元に、等値判定および比較(ソート)が行われます。
- コンピュータ屋としては、シンプルで理解しやすいルールです。
- 非バイナリ比較(言語比較) : 言語的な観点を加味して、等値判定および比較(ソート)が定義されます。
- 例) 大文字小文字の区別、濁点半濁点の区別、アクセント記号の区別など
Oracle
- 使用する照合順序を初期化パラメータNLS_COMPおよびNLS_SORTに指定します。
- デフォルトはバイナリ比較です(NLS_COMP=BINARY)。
- 非バイナリ比較(言語比較)を使うには、SQLを実行するセッションで、NLS_COMP = LINGUISTICを指定した上で、使用したい照合順序をNLS_SORTに設定します。
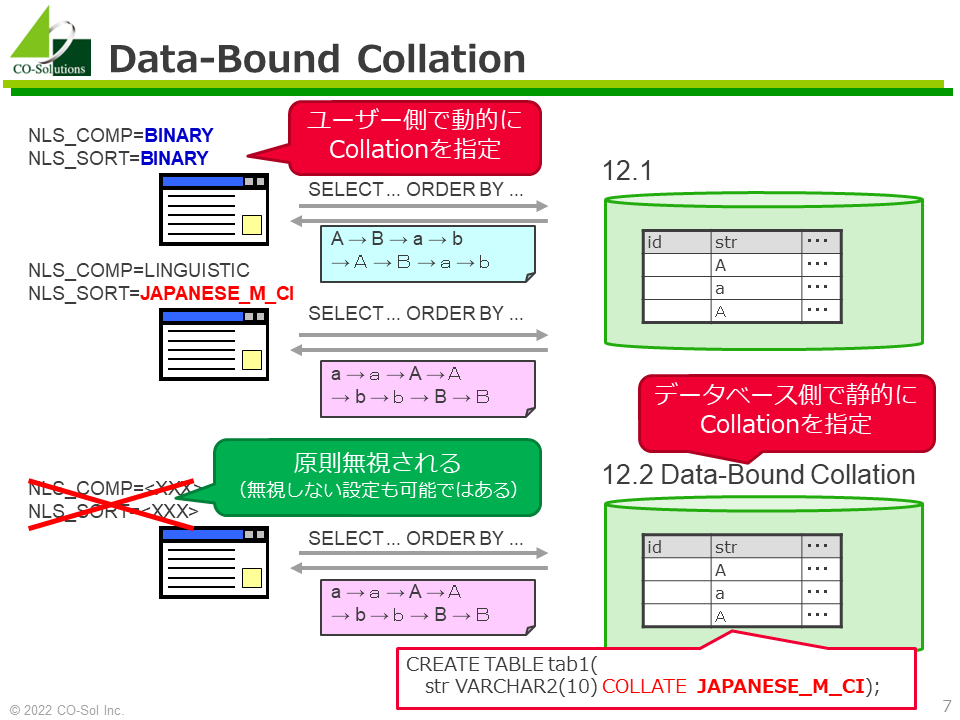
- Oracle 12.2以降ではData-Bound Collationがサポートされており、カラムに対して照合順序を指定できます。

日本語環境で使用される主な照合順序
- JAPANESE : 日本語環境向けソート
- JAPANESE_CI : 大/小文字を区別しない日本語環境向けソート
- JAPANESE_AI : アクセントも大/小文字も区別しない日本語環境向けソート
- JAPANESE_M : 日本語環境向け多言語ソート
- JAPANESE_M_CI : 大/小文字を区別しない日本語環境向け多言語ソート
- JAPANESE_M_AI : アクセントも大/小文字も区別しない日本語環境向け多言語ソート
MySQL
- 使用する照合順序を、テーブル作成時にCREATE TABLEのCOLLATE句に指定します。
- COLLATE句を省略した場合に使用される照合順序の決定ロジックは複雑です。おおまかには以下で決まります。
- 1) CREATE TABLEのCHARACTER SET句に指定した文字セットにおけるデフォルトの照合順序
- それぞれの文字セットについて、デフォルトの照合順序は、SHOW CHARACTER SET; で確認できます。
- 文字セットutf8mb4のデフォルトの照合順序はutf8mb4_0900_ai_ciです。このため、COLLATE句を省略したCREATE TABLE ... CHARACTER SET utf8mb4; では、照合順序はutf8mb4_0900_ai_ciになります。
- 2) データベースの照合順序
- COLLATE句を省略した場合に使用される照合順序の決定ロジックの詳細は https://dev.mysql.com/doc/refman/8.0/ja/charset-table.html を参照してください。
MySQLの照合順序の注意点
- 文字セットの多くで、デフォルトの照合順序が非バイナリ比較(言語比較)です。このため、COLLATE句を省略したCREATE TABLEでは、多くの場合、照合順序が非バイナリ比較(言語比較)となります。
- 文字セットutf8mb4のデフォルトの照合順序であるutf8mb4_0900_ai_ciも非バイナリ比較(言語比較)です。
- MySQLに限定されるものではありませんが、非バイナリ比較(言語比較)を使用する場合は、等値判定および比較(ソート)が、要件に合致しているかどうかチェックが必要です。
特に、文字セットutf8mb4のデフォルトの照合順序であるutf8mb4_0900_ai_ciには、以下の特徴があり、これが要件に合致しているかどうか注意が必要です。
- アクセント記号の有無が区別されない(_ai)
- 大文字小文字が区別されない(_ci)
- 「かな」の濁点、半濁点が区別されない
- 「ひらがな」と「カタカナ」が区別されない
- 促音が区別されない
- 全角記号と半角記号が区別されない
- 照合順序utf8mb4_0900_ai_ciが要件に合致しない場合、CREATE TABLEのCOLLATE句などに使用したい照合順序を明示的に指定する必要があります。
PostgreSQL
- PostgreSQLではロケールを使用しないことが多く、ロケールを使用しないと照合順序はバイナリ比較となります。
- ロケールを使用すると、照合順序は非バイナリ比較(言語比較)になります。このとき、標準ではOS(libc)の照合順序が使用されます。
- カラム単位でCREATE TABLEの列定義のCOLLATE句に指定できます(v9.1以降でサポート)。
ロケールを使用した照合順序(非バイナリ比較(言語比較))の注意点
- PostgreSQLでは、照合順序を含むロケール関係の処理はPostgreSQL外部のロケール機構(デフォルトではlibc)を使用して実装されます。このため、動作の詳細は外部のロケール機構に依存します。
- Oracle, MySQL, SQL Serverはロケール関係の処理を自前で実装しています。
- 使用できる外部のロケール機構は、以前はlibcのみでしたが、PostgreSQL 10以降でICUにも対応しました。
- インデックスの動作が照合順序に依存しているため、クエリと照合順序が対応していないと、意図したインデックスが使用されない場合があります。
- 外部のロケール機構に依存しているため、外部のロケール機構の動作変更により意図しないトラブルが発生する可能性があります(現実的にはごく稀でしょうが)。
SQL Server
- SQL Serverでは「照合順序」を、上記の (a) 文字セットと (b) 照合順序 の両方を包含した統合的な概念として使用します。
- 日本語環境におけるデフォルトの「照合順序」"Japanese_CI_AS"は非バイナリ比較(言語比較) です。
- (a) 文字セット : "Japanese" → シフトJIS相当(日本語Windowsでの標準的な文字コード)
- (b) 照合順序 : "_CI_AS" → 大文字小文字を区別しない(Case Insensitive) + アクセント記号を区別する(Accent Sensitive)
日本語環境におけるデフォルト「照合順序」"Japanese_CI_AS"の注意点
- 非バイナリ比較(言語比較)です。"_CI_AS"オプションが指定されているため、 大文字小文字を区別しない(Case Insensitive) + アクセント記号を区別する(Accent Sensitive)となり、この動作が要件に合致しているかどうかチェックが必要です。
- 文字セットはシフトJIS相当です。Unicodeはサポートしません。
「主要RDBMS製品の比較」ページ一覧
- アーキテクチャ, スキーマ, データベース, メモリ
https://cosol.jp/techdb/2022/09/rdbms_architecture_comparison/
- 記憶域, トランザクションログ, 物理構造
https://cosol.jp/techdb/2022/09/rdbms_compare_storage/
- バックアップ, 災害対策構成, 論理レプリケーション
https://cosol.jp/techdb/2022/09/rdbms_compare_bk_dr_rep/
- 同時実行制御, トランザクション分離レベル
https://cosol.jp/techdb/2022/09/rdbms_compare_conc_cntl_transaction/
- 文字コード, 文字セット, 照合順序
https://cosol.jp/techdb/2022/09/rdbms_compare_charcode/
- 接続, ユーザー, コマンドラインクライアント
https://cosol.jp/techdb/2022/09/rdbms_compare_conn_user/
[PR] オンプレミス&クラウドのマルチDB製品に対応した性能管理ツールDPA
Database Performance Analyzer (DPA) は、オンプレミス&クラウドに対応するデータベース性能監視/分析ツールです。
この記事で取り上げたRDBMS製品を含む、非常に多くのデータベース製品/サービスに対応しています。
- Oracle Database
- MS SQL Server
- Sybase SAP ASE
- IBM Db2
- MySQL / MariaDB / Percona Server for MySQL
- PostgreSQL / Enterprise DB
- AWS
- Amazon RDS for Oracle Database / SQL Server / MySQL / MariaDB / PostgreSQL
- Amazon Aurora for MySQL / PostgreSQL
- Azure
- Azure SQL Database
- Azure SQL Managed Instance
- Azure SQL for PostgreSQL
- Azure Database for MySQL / MariaDB
- Google Cloud
- Google Cloud SQL for MySQL / PostgreSQL / SQL Server
以下の特徴があり、導入しやすく有用な製品です。
なぜコーソルからDatabase Performance Analyzer (DPA)を購入すべきなのか
コーソルはDatabase Performance Analyzer (DPA)の一次代理店で、Database Performance Analyzer (DPA)の製品販売を行います。 SIer様、販社様がDatabase Performance Analyzer (DPA)を販売および導入することも可能です。
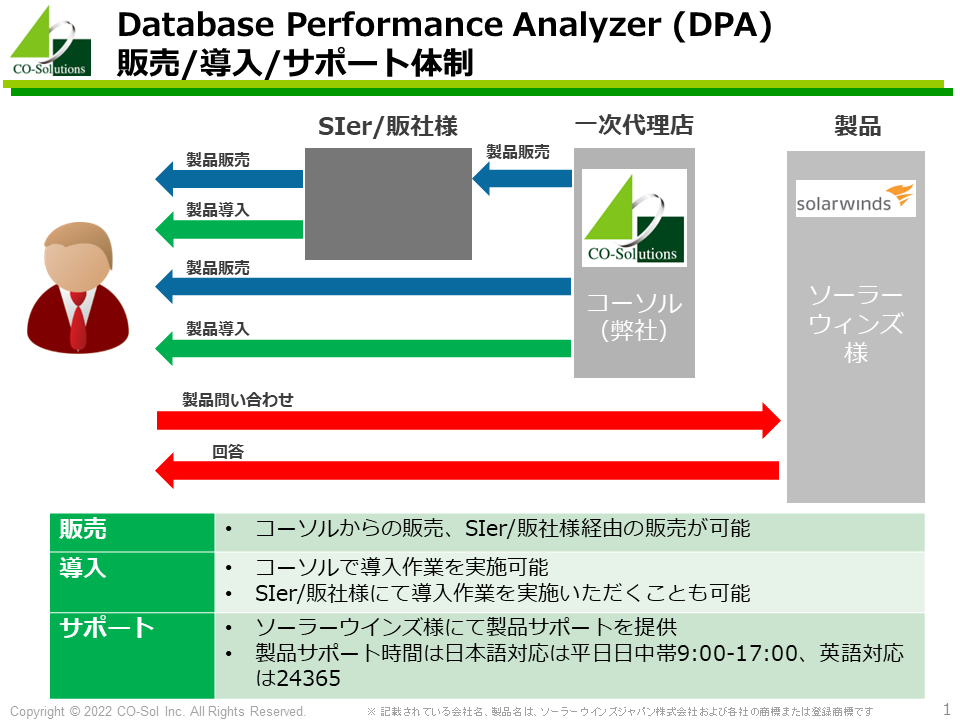
コーソルはデータベースの技術力を強みとしています。なかでもOracle Database技術力は日本随一です。MySQL、PostgreSQL、MS SQL Serverの資格や実績を持つエンジニアも多数在籍しております。
独自のDPAナレッジを公開
DPAの導入や監視設定に関する手順をナレッジとして公開しています。評価版をご利用される際の参考にしていただけると幸いです。
多数のOracle関連書籍を執筆

- [改訂2版] Oracleの基本 ~データベース入門から設計/運用の初歩まで : 渡部 亮太 , 舛井 智行, 岡野 平八郎, 峯岸 隆一, 日比野 峻佑, 相川潔
https://www.amazon.co.jp/dp/429712954X (2022年7月16日発売)
- オラクルマスター教科書 Gold DBA Oracle Database Administration II : 渡部 亮太 , 舛井 智行, 峯岸 隆一
https://www.amazon.co.jp/dp/479817436X/ (2022年5月27日 発売)
- オラクルマスター教科書 Silver SQL Oracle Database SQL : 渡部 亮太 , 舛井 智行, 峯岸 隆一
https://www.amazon.co.jp/dp/4798172367/ (2021年9月13日 発売)
- オラクルマスター教科書 Silver DBA Oracle Database Administration I : 渡部 亮太 , 舛井 智行 , 杉本 篤信 , 西田 幸平
https://www.amazon.co.jp/dp/4798166359/ (2021年5月28日 発売)
- オラクルマスター教科書 Bronze DBA Oracle Database Fundamentals : 渡部 亮太 , 岡野 平八郎 , 鈴木 俊也
https://www.amazon.co.jp/dp/4798166367/ (2020年9月17日 発売)
- オラクルマスター教科書 Gold Oracle Database 12c : 渡部 亮太 , 岡野 平八郎
https://www.amazon.co.jp/dp/4798147958/ (2018年8月8日 発売)
- Oracleの基本 ~ データベース入門から設計/運用の初歩まで : 渡部 亮太 , 相川 潔 , 日比野 峻佑 , 岡野 平八郎 , 宮川 大地
https://www.amazon.co.jp/dp/4774192511/ (2017年9月22日 発売)
- プロとしてのOracleアーキテクチャ入門【第2版】 : 渡部 亮太
http://www.amazon.co.jp/dp/4797384085/ (2015年4月25日 発売)
- プロとしてのOracle運用管理入門 : 渡部 亮太
http://www.amazon.co.jp/dp/4797355123/ (2009年9月25日 発売)
- プロとしてのOracleアーキテクチャ入門 : 渡部 亮太 , 森坂 康人
http://www.amazon.co.jp/dp/4797349808/ (2008年8月22日 発売)
- プロとしてのOracle入門 : 松下 雅, 舛井 智行, 古賀 加奈
http://www.amazon.co.jp/dp/4797349433/ (2008年10月29日 発売)
- Oracle Database 10g Oracle Enterprise Manager 逆引きクイックリファレンス : 舛井 智行, 青木 武士, 松下 雅
http://www.amazon.co.jp/dp/4797349433/ (2007年11月27日 発売)
ORACLE MASTER Platinum取得者数 No.1
- 単年度ORACLE MASTER Platinum取得者数7年連続No.1
7年連続ORACLE MASTER Platinum取得者数No.1! Oracle Certification Award 2020
- 累計ORACLE MASTER Platinum取得者数も、2016年以降No.1を維持
[PR] コーソルのデータベース運用関連製品とサービス
コーソルでは、データベース運用を製品とサービスでご支援します。
Database Performance Analyzer (DPA)
Database Performance Analyzer (DPA)は、オンプレミスとクラウド上の多くのデータベース製品に対応したデータベース性能管理製品です。低価格であるため、非常に導入しやすいです。
自動SQLチューニング機能を持つToad
Database Performance Analyzer (DPA)で検出された問題SQLをチューニングする際に、Toad for Oracle / Toad for SQL Serverの SQL Optimizer機能を使用できます。
リモートDBAサービス
リモートDBAサービスはDB・運用の専門家がお客様のデータベースに対して
必要な時に必要な対応を行うリモート接続型運用保守サービスです。
データベース運用保守なら常駐しないリモートDBA
時間制コンサルティングサービス
時間制コンサルティングサービスは”必要な時に” ”必要な時間だけ”契約できる
時間契約型のコンサルティングサービスです。
データベース コンサルティングなら時間制コンサルティング


