主要RDBMS製品の比較 – 記憶域, トランザクションログ, 物理構造
Oracle ACE Proの渡部です。
主要なRDBMS製品を比較します。
- 目的は大枠の整理です。細かい例外事項や拡張機能は適宜記載を割愛しています。
- 2022年9月時点の最新バージョンをベースに記載していますが、記載内容にバージョン依存は少ないはずです。
- 時間ができた時に随時追記予定です。
- もし誤りを見つけた場合は、優しく教えていただけると嬉しいです。→ https://twitter.com/wrcsus4 or ryota.watabe at cosol dot jp
「主要RDBMS製品の比較」ページ一覧
- アーキテクチャ, スキーマ, データベース, メモリ
https://cosol.jp/techdb/2022/09/rdbms_architecture_comparison/
- 記憶域, トランザクションログ, 物理構造
https://cosol.jp/techdb/2022/09/rdbms_compare_storage/
- バックアップ, 災害対策構成, 論理レプリケーション
https://cosol.jp/techdb/2022/09/rdbms_compare_bk_dr_rep/
- 同時実行制御, トランザクション分離レベル
https://cosol.jp/techdb/2022/09/rdbms_compare_conc_cntl_transaction/
- 文字コード, 文字セット, 照合順序
https://cosol.jp/techdb/2022/09/rdbms_compare_charcode/
- 接続, ユーザー, コマンドラインクライアント
https://cosol.jp/techdb/2022/09/rdbms_compare_conn_user/
立場の表明
- コーソルはデータベース関連製品の販売およびプロフェッショナルサービス提供を行っている営利企業です。
- https://cosol.jp にある全てのコンテンツは、情報提供に加えて、コーソルの認知度向上、コーソルの営利活動の促進を目的としています。


著者について

データ格納用の記憶域
- ディスク分散(I/O分散)、領域の事前・事後割り当てを中心に整理します。
- MySQLの「テーブルスペース」、PostgreSQLの「テーブル空間」は図では「表領域」と表記します。
- 訳語が異なるだけで、実は英語では同じ"tablespace"
私見など
- Oracleは、領域を事前割り当てする指向が強い気がします。
- いずれのRDBMS製品も「表領域」相当の概念を持ちますが、MySQL、PostgreSQL、MS SQL Serverはその存在をうまく隠し、「必要になったときに理解すればよい」ような工夫がされているように思えます。
Oracle
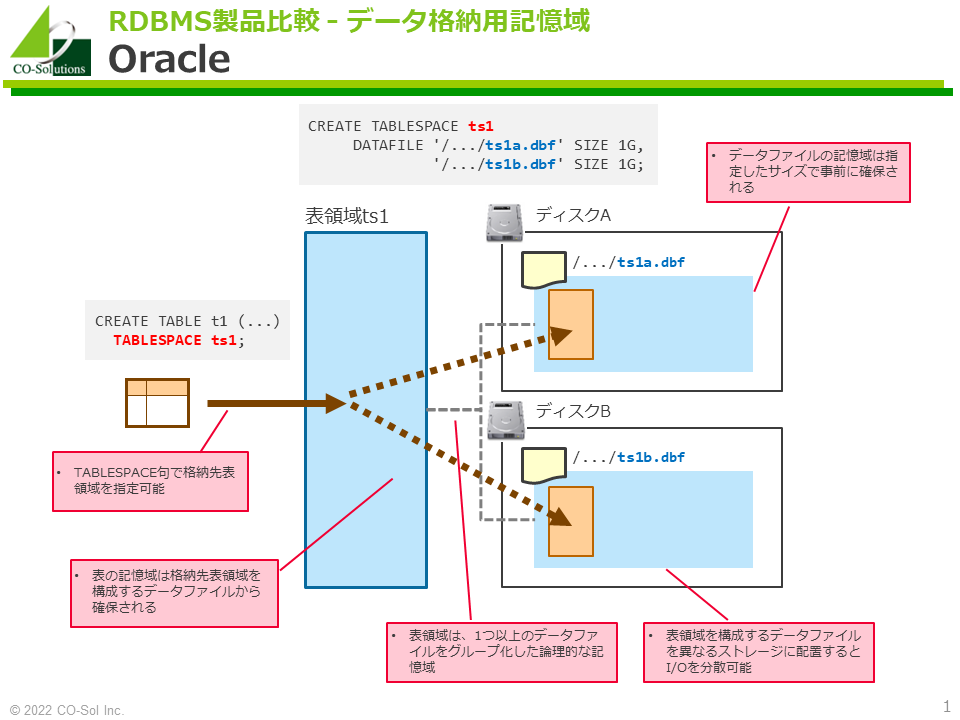
- 1つ以上のデータファイルをグループ化した論理的な記憶域として表領域があります。データを格納するための表領域は永続表領域です。
- CREATE TABLESPACE文で、ユーザーがデータを格納するための永続表領域を作成できます。
- テーブル作成時に、TABLESPACE句で格納先となる永続表領域を指定できます。永続表領域の指定を省略すると、ユーザーのデフォルト表領域に格納されます。
- 表領域を構成するデータファイルを異なるストレージに配置するとI/Oを分散できます。
Oracleにはいくつかの特殊な表領域があります。表領域の構成はカスタマイズ可能であるため、一例として、DBCAを用いてデータベースを作成した時に構成される表領域を以下に示します。
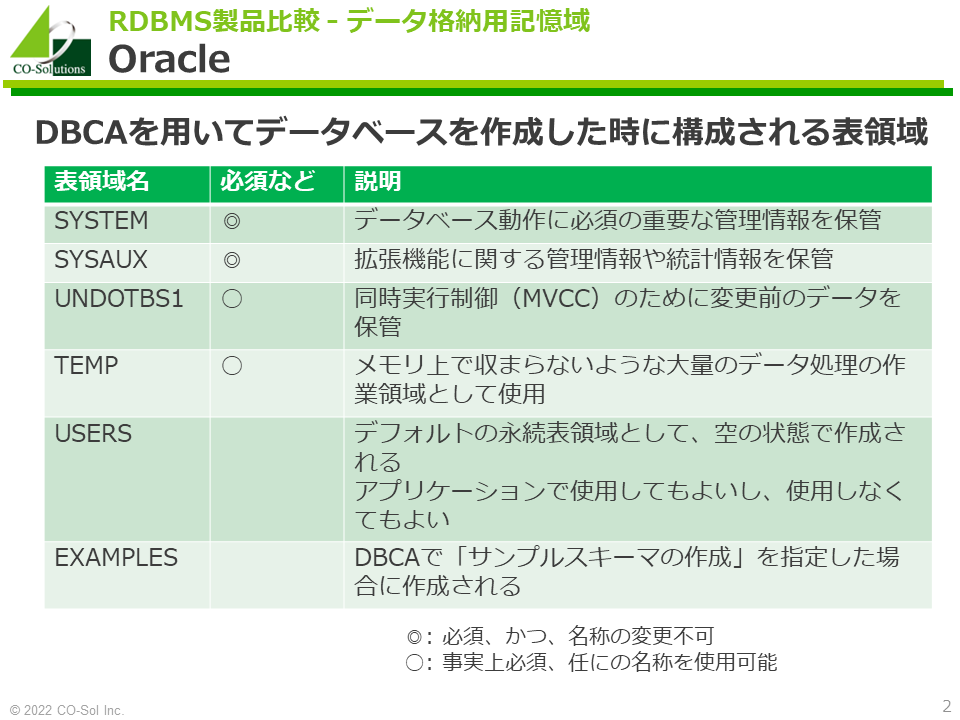
- SYSTEM : データベース動作に必須の重要な管理情報を保管
- SYSAUX : 拡張機能に関する管理情報や統計情報を保管
- UNDOTBS1 : 同時実行制御(MVCC)のために変更前のデータを保管
- TEMP : メモリ上で収まらないような大量のデータ処理の作業領域として使用
- USERS : デフォルトの永続表領域として、空の状態で作成される。アプリケーションで使用してもよいし、使用しなくてもよい
- EXAMPLES : DBCAで「サンプルスキーマの作成」を指定した場合に作成される
補足 Oracle ASM
データファイルを異なるストレージに配置するとI/Oを分散できますが、I/O量を事前に把握して適切に分散することはなかなか大変です。Oracle ASMを使用すると、I/O分散をはじめとするストレージにまつわる様々な問題を解決できます。
MySQL (InnoDB/File-Per-Table)
MySQLでは、設定に応じて記憶域の扱いが大きく異なるため、一般的な使用形態およびデフォルトを踏まえた以下を前提に説明します。
- InnoDBストレージエンジン
- File-Per-Tableテーブルスペース(innodb_file_per_table=ON)
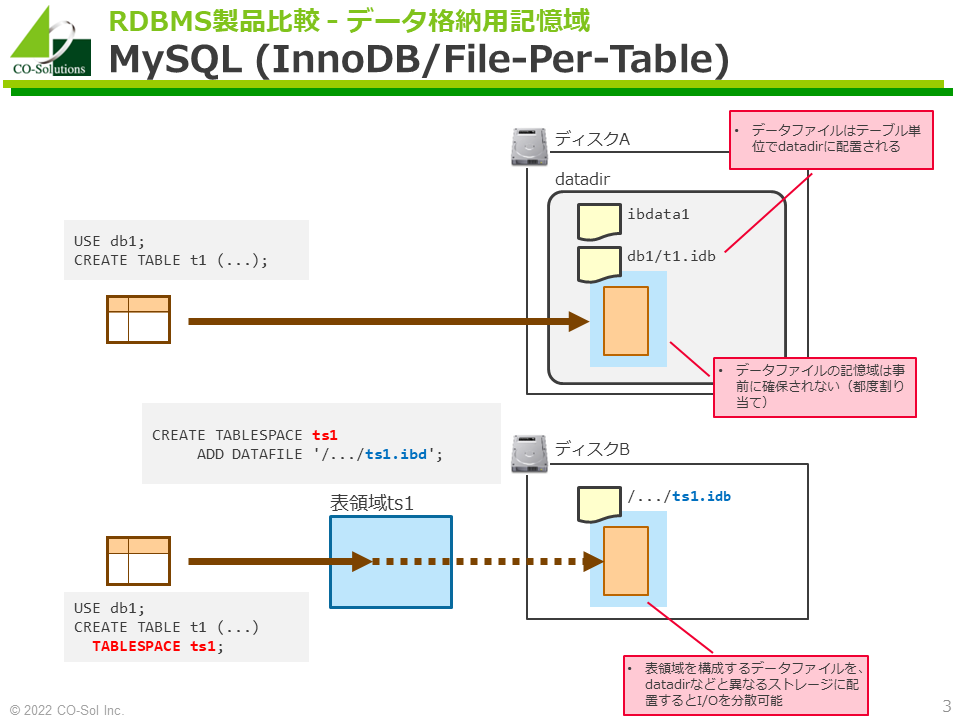
データベースdb1にテーブルt1を作成すると、datadir以下のファイル構成(抜粋)は以下になります(2022/9/12修正、yoku-san ご指摘ありがとうございます!)。
ibdata1 : その他の管理情報が格納される(システムテーブルスペース)
db1/t1.ibd : テーブルt1のデータが格納される
なお、MySQL 5.7から「一般テーブルスペース」(いわゆる「表領域」)が導入されています。以下の特性を持ち、Oracleの表領域にとてもよく似ています。
- CREATE TABLESPACE文で一般テーブルスペースを作成できます。一般テーブルスペースの実体は、その表領域に格納されたテーブルやインデックスを格納する共有のデータファイルです。
- 作成したテーブルスペースはテーブルスペース名で識別されます。
- テーブルの作成時に、TABLESPACE句で格納先となるテーブルスペースを指定できます。
PostgreSQL
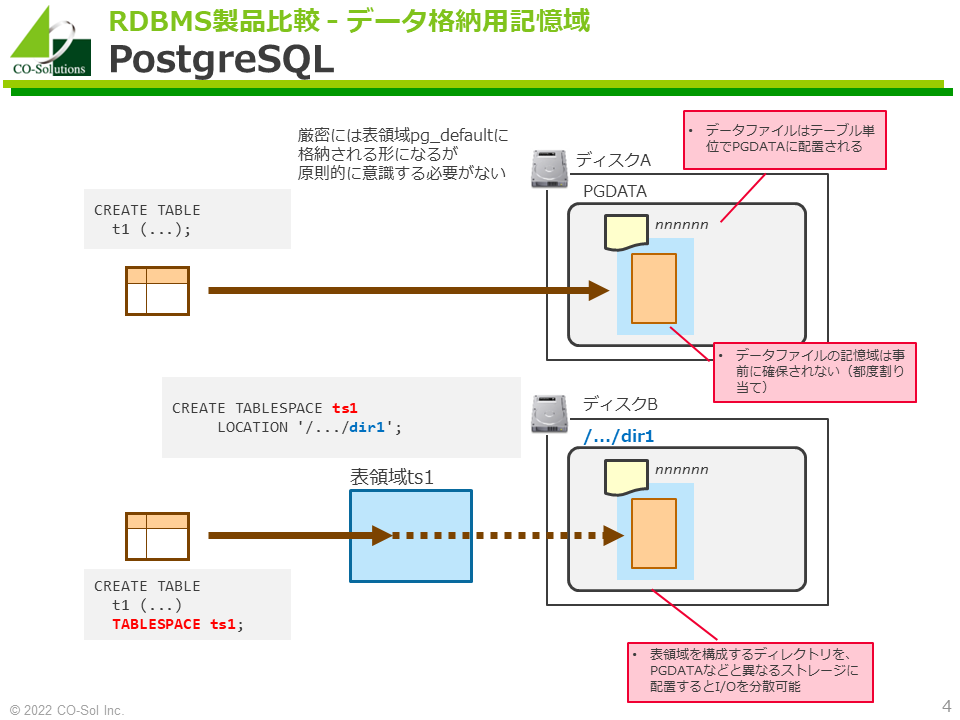
- データファイルはテーブル単位でPGDATAに配置されます。
- データファイルの記憶域は事前に確保されません。使用量の増加に伴い、都度、追加の記憶域割り当てられます。
- CREATE TABLESPACE文でテーブル空間(表領域)を作成できます。テーブル空間の実体はデータファイルを配置するためのディレクトリです。
- テーブル空間を構成するディレクトリを、PGDATAなどと異なるストレージに配置するとI/O負荷を分散できます。
- テーブルの作成時に、TABLESPACE句で格納先となるテーブル空間を指定できます。
- TABLESPACE句の指定を省略した場合に、格納先となるテーブル空間は、default_tablespaceパラメータに指定できます。
- データベースのデフォルトのテーブル空間を指定することもできます。
PostgreSQLはテーブルスペースの存在を意識しなくても使用できますが、実は初期状態で以下の表領域が存在します。
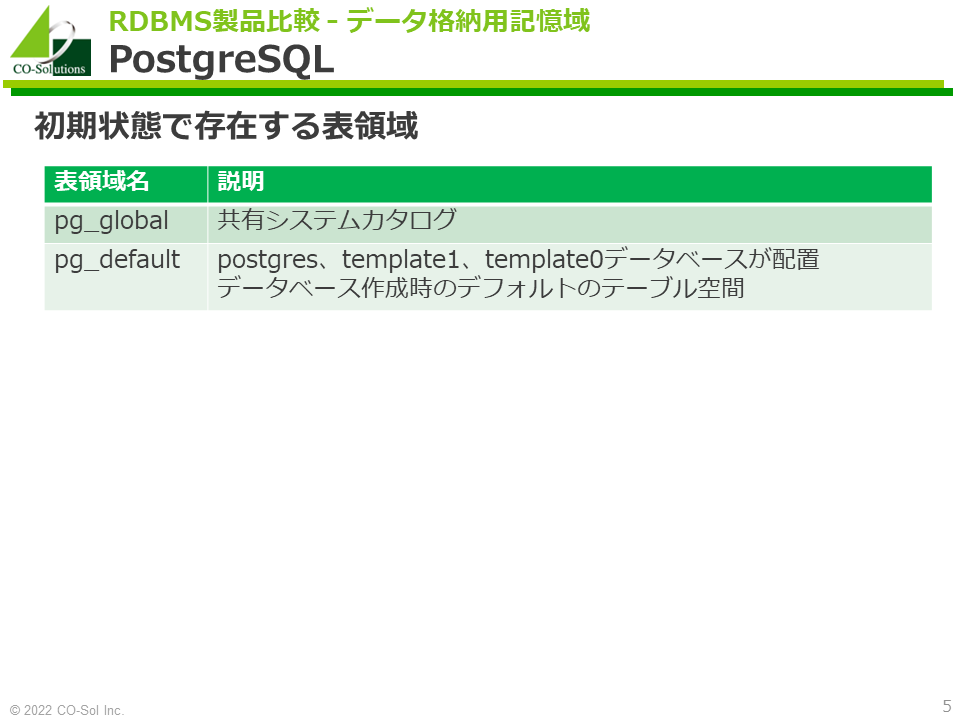
MS SQL Server
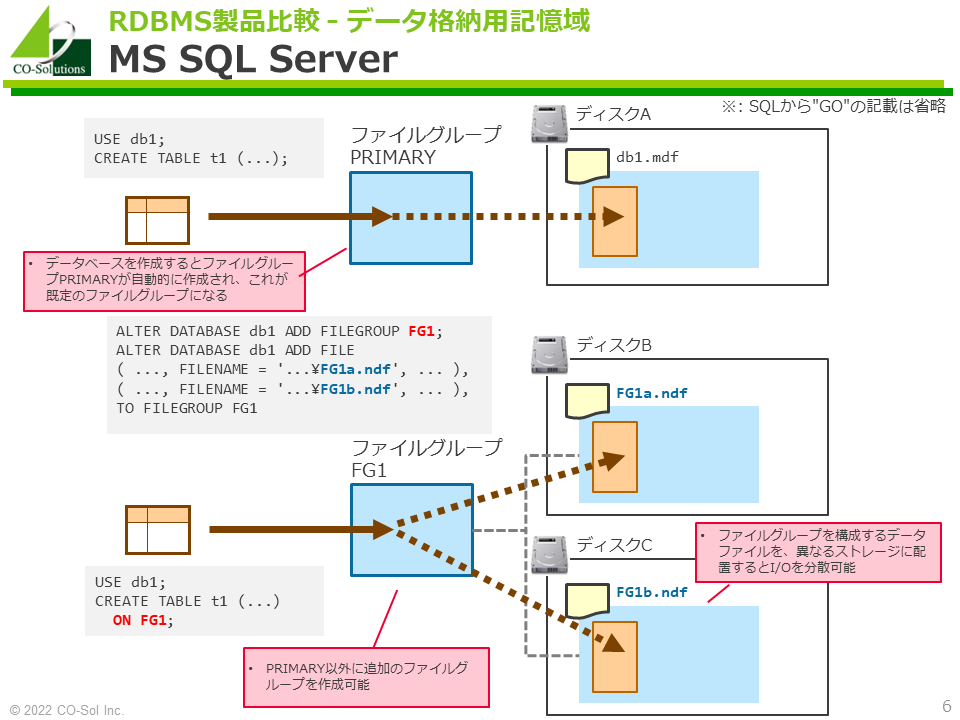
- データベースを作成するとファイルグループPRIMARYが自動的に作成され、これが既定のファイルグループになります。
- テーブルを作成すると、デフォルトで既定のファイルグループ(≒ファイルグループPRIMARY)に格納されます。このため、ファイルグループの存在を特に意識しなくても使えます。
- PRIMARY以外に追加のファイルグループを作成できます。
- ファイルグループを構成するデータファイルを、異なるストレージに配置するとI/Oを分散できます。
トランザクションログ
トランザクションログ周辺のデータキャッシュ、データファイル、トランザクションログファイルのアーキテクチャは、製品間で比較的よく似ており、以下に記載する「教科書的なアーキテクチャ」を基本的に踏襲しています。
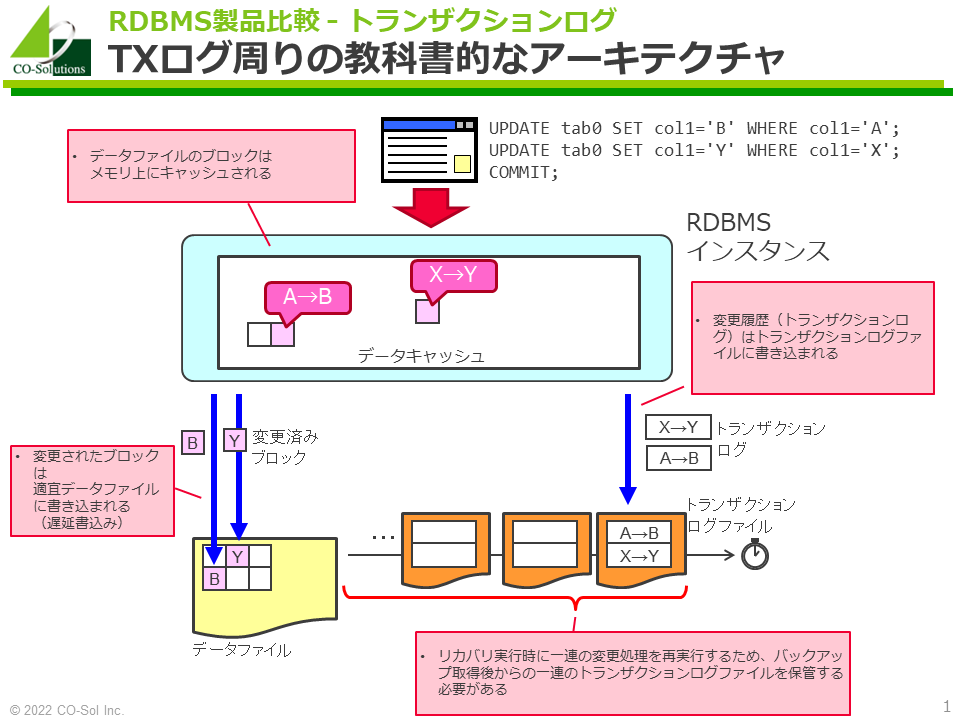
- 読み込み及び書込み処理の効率化のため、データファイルのブロックはメモリ上にキャッシュおよびバッファリングされます。
- 変更されたブロックは、すぐにデータファイルに書き込まれるのではなく、あとで適宜データファイルに書き込まれます(遅延書込み)。
- その一方で、変更の消失を防ぐため、変更履歴(トランザクションログ)はトランザクションログファイルに速やかに(コミット実行後など)書き込まれます。
- データファイル破損などの障害から復旧する場合、一連の変更処理を再実行する必要がでてきます。このため、バックアップ取得後からの一連のトランザクションログファイルを保管する必要があります。
Oracle
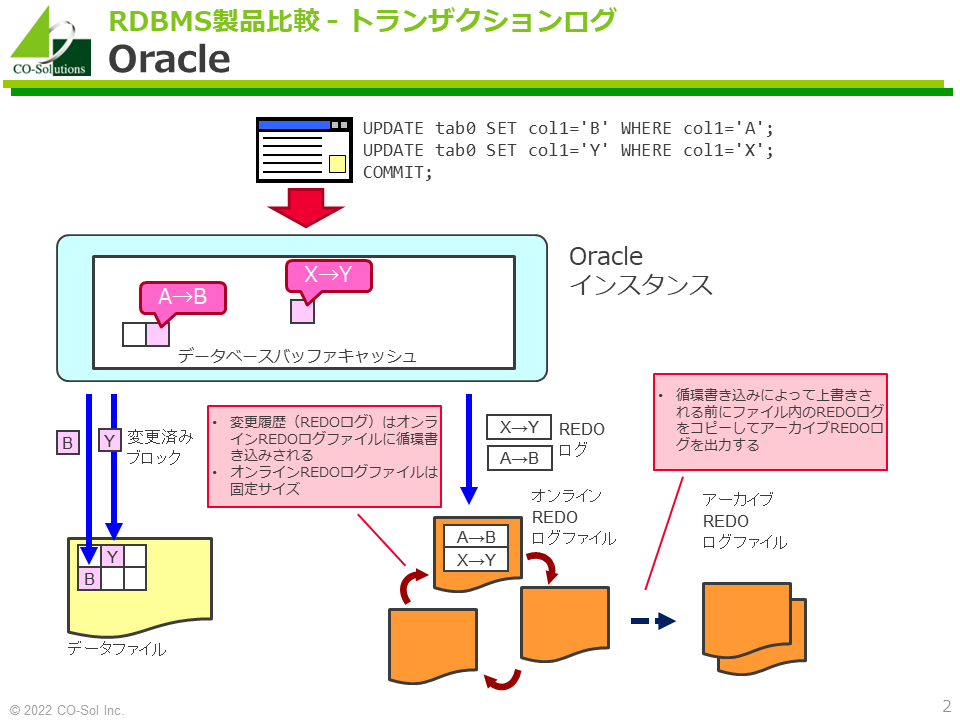
- 変更履歴(REDOログ)はオンラインREDOログファイルに循環書き込みされます。
- オンラインREDOログファイルは固定サイズで自動拡張されません。
- 循環書き込みによって上書きされる前にファイル内のREDOログをコピーしてアーカイブREDOログを出力します(アーカイブログモード)
- 図には記載していませんが、オンラインREDOログファイルを多重化する仕組みがあります(メンバ)。「トランザクションログが失われる=障害発生時に変更が失われる」であるため、オンラインREDOログファイルの多重化は変更の保護に大きく寄与します。
MySQL (InnoDB)
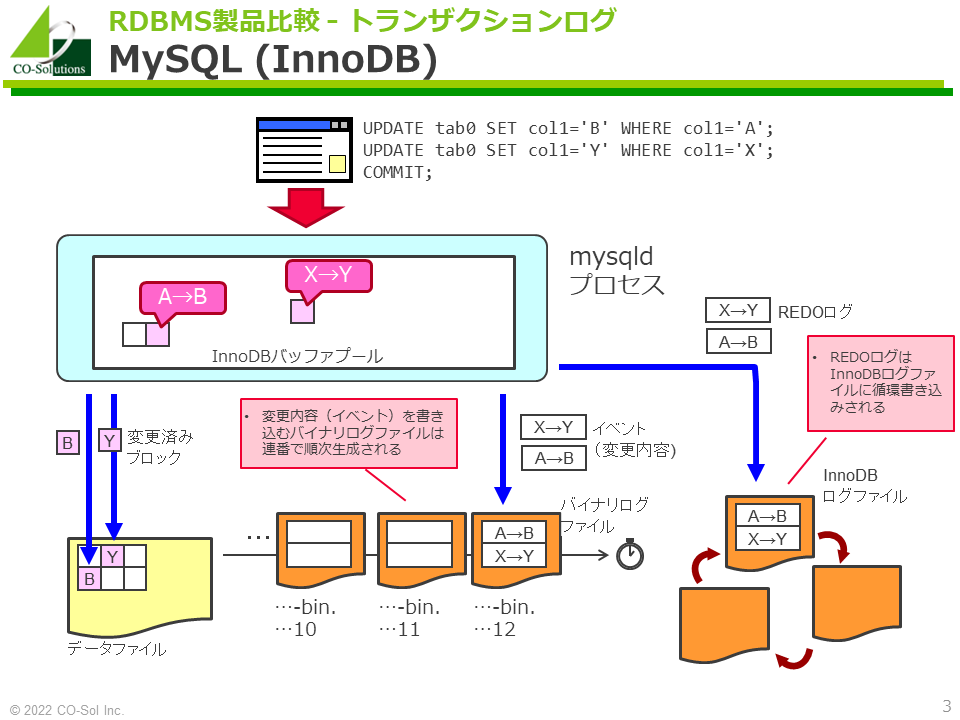
- おそらく歴史的な事情などから、MySQLにはInnoDBログファイルとバイナリログファイルという2種類のトランザクションログファイルがあります。
- それぞれ用途が異なります。
- InnoDBログファイル : クラッシュリカバリ
- バイナリログファイル : メディアリカバリ、レプリケーション
- REDOログはInnoDBログファイルに循環書き込みされます。
- 変更処理(イベント)を書き込むバイナリログファイルは連番で順次生成されます。
PostgreSQL
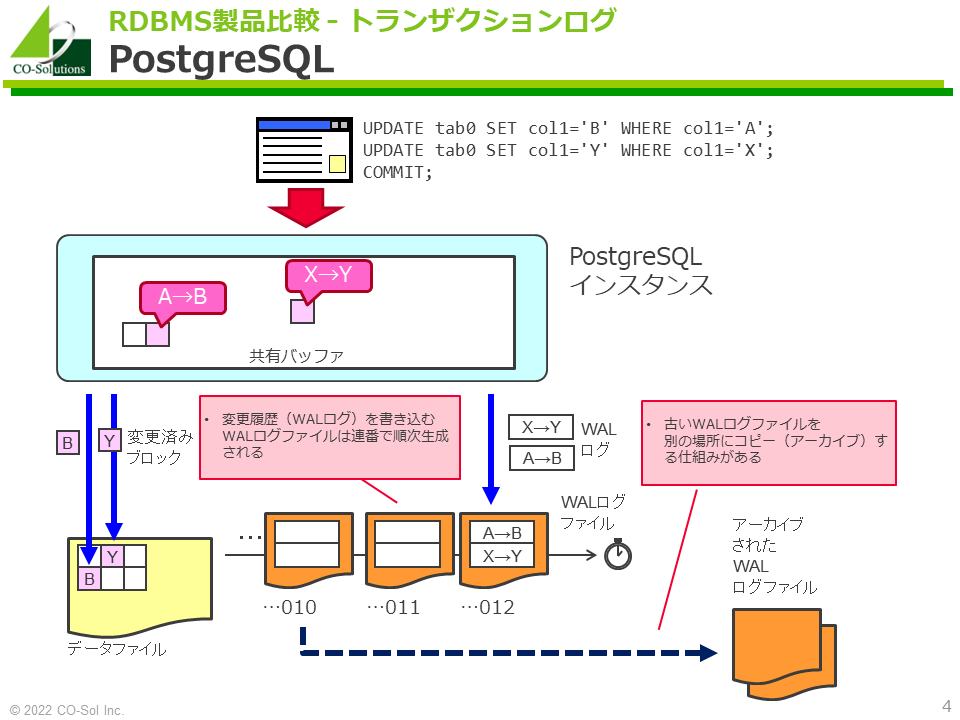
- 変更履歴(WALログ)を書き込むWALログファイルは連番で順次生成されます
- 古いWALログファイルを別の場所にコピー(アーカイブ)する仕組みがあります。
MS SQL Server
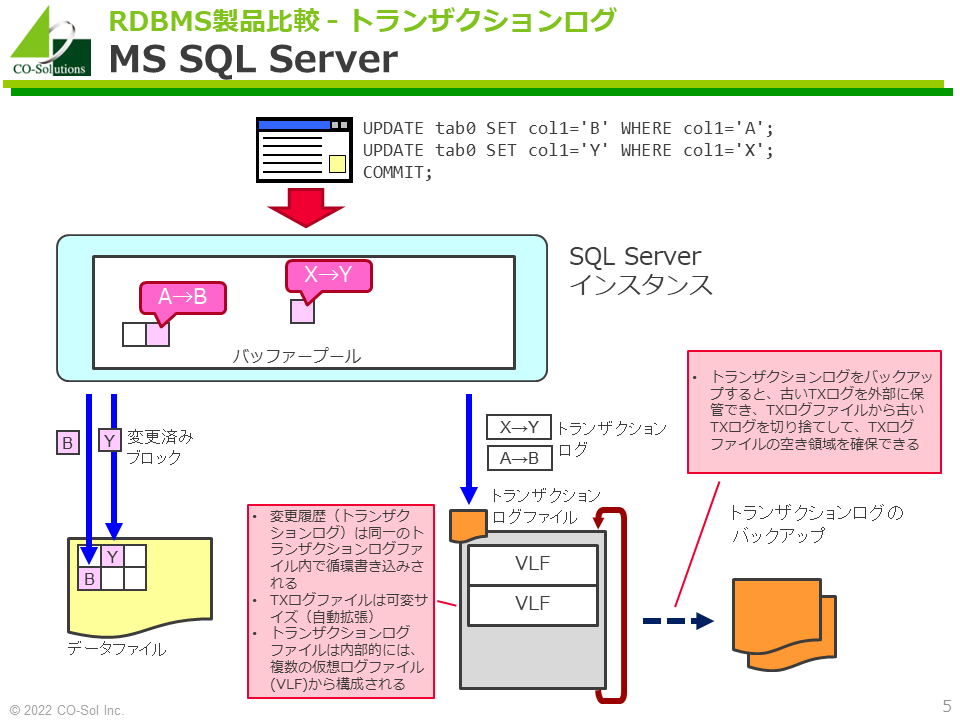
- 変更履歴(トランザクションログ)は同一のトランザクションログファイル内で循環書き込みされます。
- トランザクションログファイルは内部的には、複数の仮想ログファイル(VLF)から構成されます。
- トランザクションログをバックアップすると、古いトランザクションログを外部に保管できます。加えて、トランザクションファイルから古いトランザクションログを切り捨てて、トランザクションファイルの空き領域を確保できます。
- 明示的に「トランザクションログをバックアップしないと、トランザクションログをリカバリ処理に使用できない」という制約は、Oracleに慣れたエンジニアからすると、かなり不思議に感じるところです。
- トランザクションログファイルはデータベース毎に存在します。インスタンス単位ではありません。
テーブルの物理構造
- 最も一般的なテーブルおよびインデックス(Bツリーインデックス)に限定して記載します。
- パーティション、列指向、インメモリ、Bツリー以外のインデックスなど高度な機能については記載していません。
Oracle
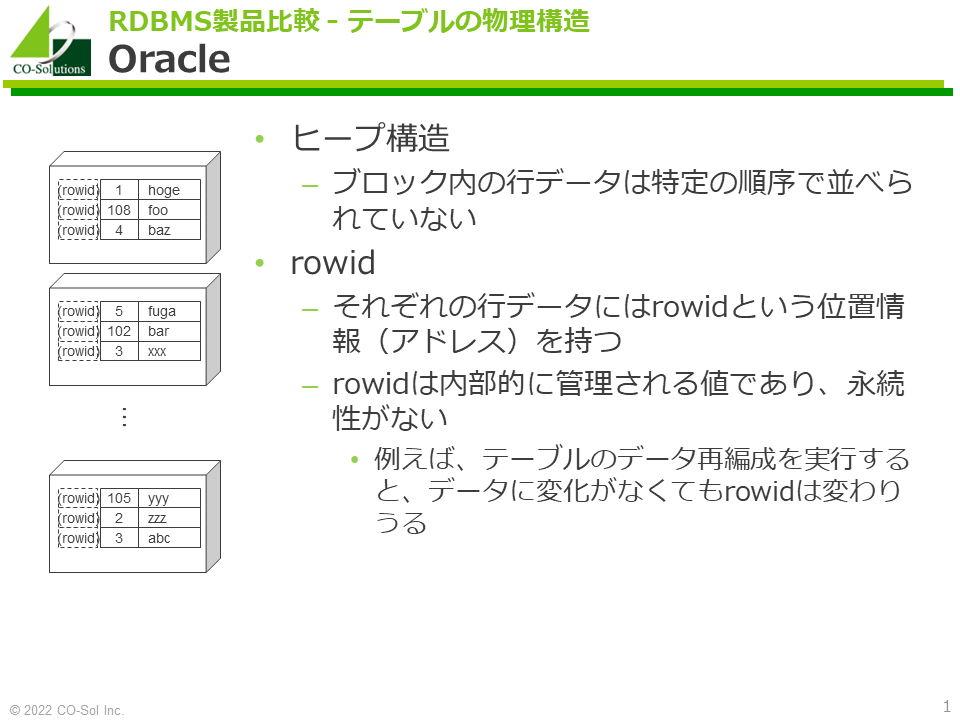
- いわゆる「ヒープ構造」です。ブロック内の行データは特定の順序で並べられていません。
- それぞれの行データにはrowidという位置情報(アドレス)を持ちます。
- rowidは内部的に管理される値であり、永続性がありません。例えば、テーブルのデータ再編成を実行すると、データに変化がなくてもrowidは変わる可能性があります。
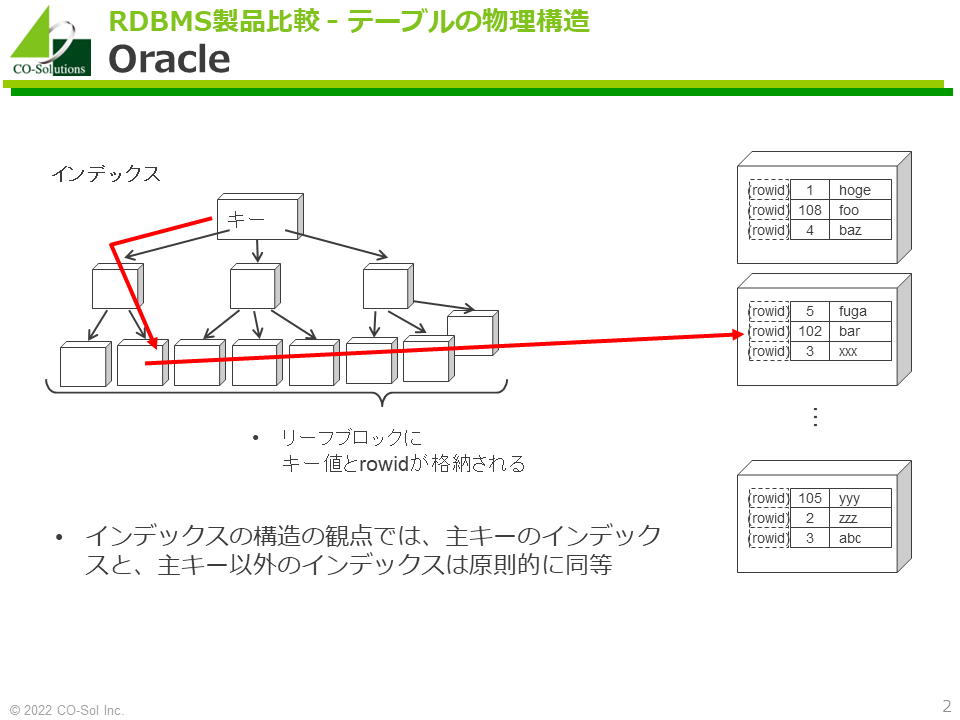
-
インデックスは木構造をしており、末端のリーフブロックに索引列の値(キー値)とその行に対応するrowidが格納されます。
-
インデックスの木構造を辿ると、対象の行に少ないI/O回数でアクセスできる(読み取るべきブロック数が少ない)ため、データが少量であれば高速にアクセスできます。
-
インデックスの構造の観点では、主キーのインデックスと、主キー以外のインデックスは原則的に同等です。
-
後述する「クラスタ化インデックス」も、索引構成表(IOT, Index Organized Table)としてサポートしています。
MySQL (InnoDB)
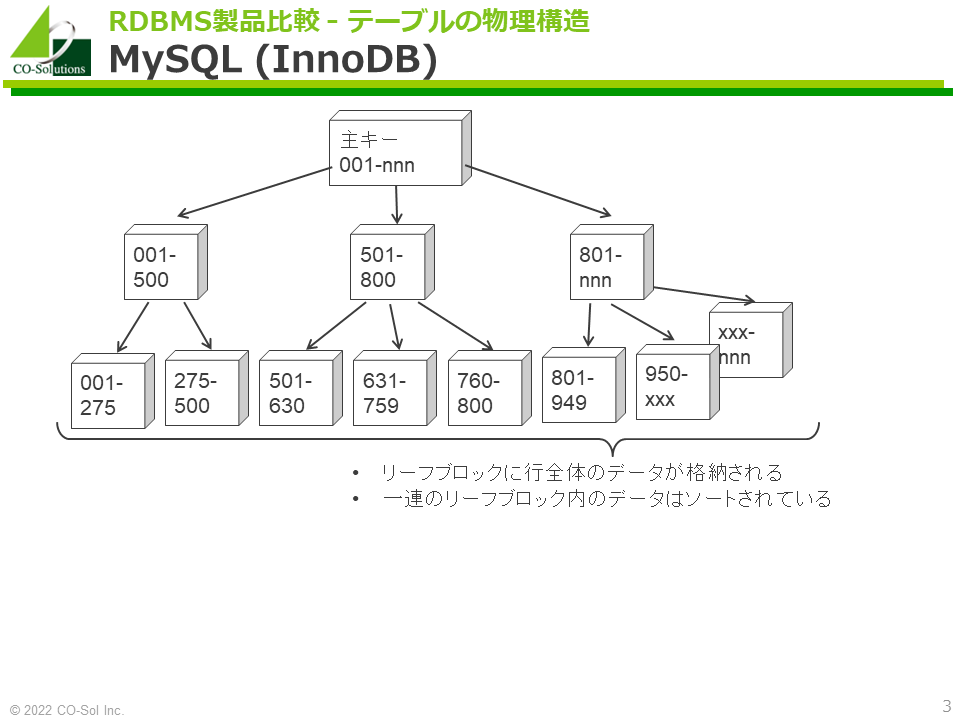
- テーブルと「主キーを索引列としたインデックス」が一体化したような構造をしています。インデックスのリーフブロックに、索引列以外の列を含めた行全体のデータが格納されます。これを一般に「クラスタ化インデックス」と呼びます。
- リーフブロックに含まれるデータはソートされているため、テーブルとしたみたときも、データがソートされていることになります。
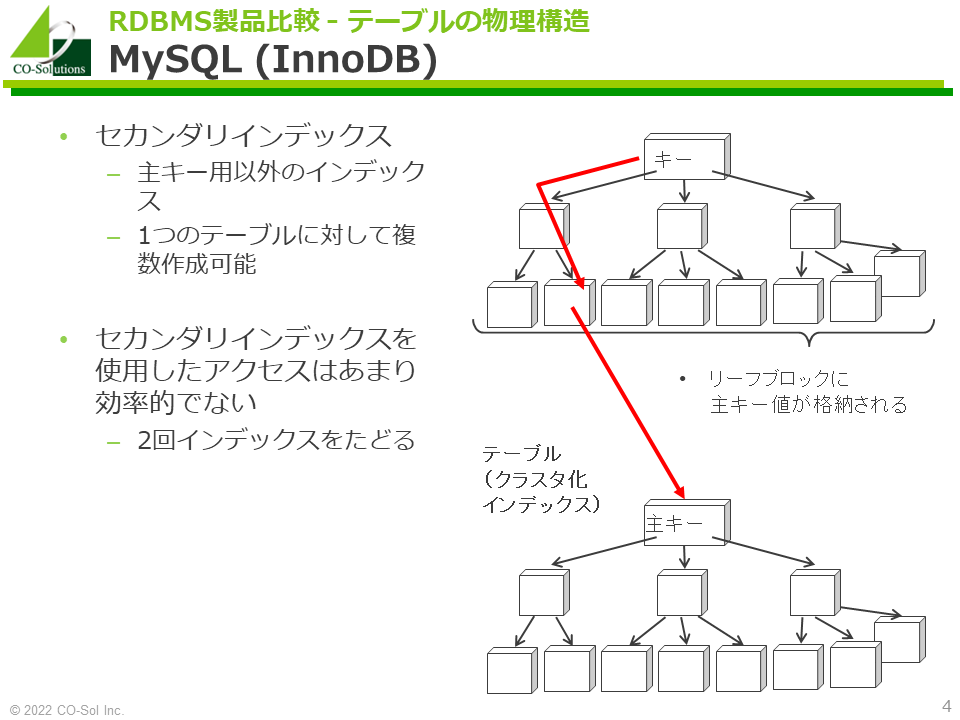
- 主キー以外を索引列にしたインデックスを複数作成できます(セカンダリインデックス)。
- セカンダリインデックスのリーフブロックには、索引列と対象行の主キー値が含まれます。
- 以下のステップで、対象行にアクセスできます。
- セカンダリインデックスの木構造を辿る
- 対象行の主キー値を得る
- 対象行の主キー値を元に、クラスタ化インデックスの木構造を辿る
PostgreSQL
- Oracleに類似した構造です。
- ブロック内の行は追記型です(時間があれば追記予定)
MS SQL Server
(2022/9/12修正、tjtakahashi-san ありがとうございます!)
- デフォルトのテーブルの構造は「クラスタ化インデックス」です。
- セカンダリインデックスなどのクラスタ化インデックス周辺の動作は、MySQL InnoDBと同様です。
- 主キーが定義されていない場合は、「ヒープ構造」となります。
[余談] クラスタ化インデックスとヒープ構造の長所短所に関する議論
「主要RDBMS製品の比較」ページ一覧
- アーキテクチャ, スキーマ, データベース, メモリ
https://cosol.jp/techdb/2022/09/rdbms_architecture_comparison/
- 記憶域, トランザクションログ, 物理構造
https://cosol.jp/techdb/2022/09/rdbms_compare_storage/
- バックアップ, 災害対策構成, 論理レプリケーション
https://cosol.jp/techdb/2022/09/rdbms_compare_bk_dr_rep/
- 同時実行制御, トランザクション分離レベル
https://cosol.jp/techdb/2022/09/rdbms_compare_conc_cntl_transaction/
- 文字コード, 文字セット, 照合順序
https://cosol.jp/techdb/2022/09/rdbms_compare_charcode/
- 接続, ユーザー, コマンドラインクライアント
https://cosol.jp/techdb/2022/09/rdbms_compare_conn_user/
[PR] オンプレミス&クラウドのマルチDB製品に対応した性能管理ツールDPA
Database Performance Analyzer (DPA) は、オンプレミス&クラウドに対応するデータベース性能監視/分析ツールです。
この記事で取り上げたRDBMS製品を含む、非常に多くのデータベース製品/サービスに対応しています。
- Oracle Database
- MS SQL Server
- Sybase SAP ASE
- IBM Db2
- MySQL / MariaDB / Percona Server for MySQL
- PostgreSQL / Enterprise DB
- AWS
- Amazon RDS for Oracle Database / SQL Server / MySQL / MariaDB / PostgreSQL
- Amazon Aurora for MySQL / PostgreSQL
- Azure
- Azure SQL Database
- Azure SQL Managed Instance
- Azure SQL for PostgreSQL
- Azure Database for MySQL / MariaDB
- Google Cloud
- Google Cloud SQL for MySQL / PostgreSQL / SQL Server
以下の特徴があり、導入しやすく有用な製品です。
なぜコーソルからDatabase Performance Analyzer (DPA)を購入すべきなのか
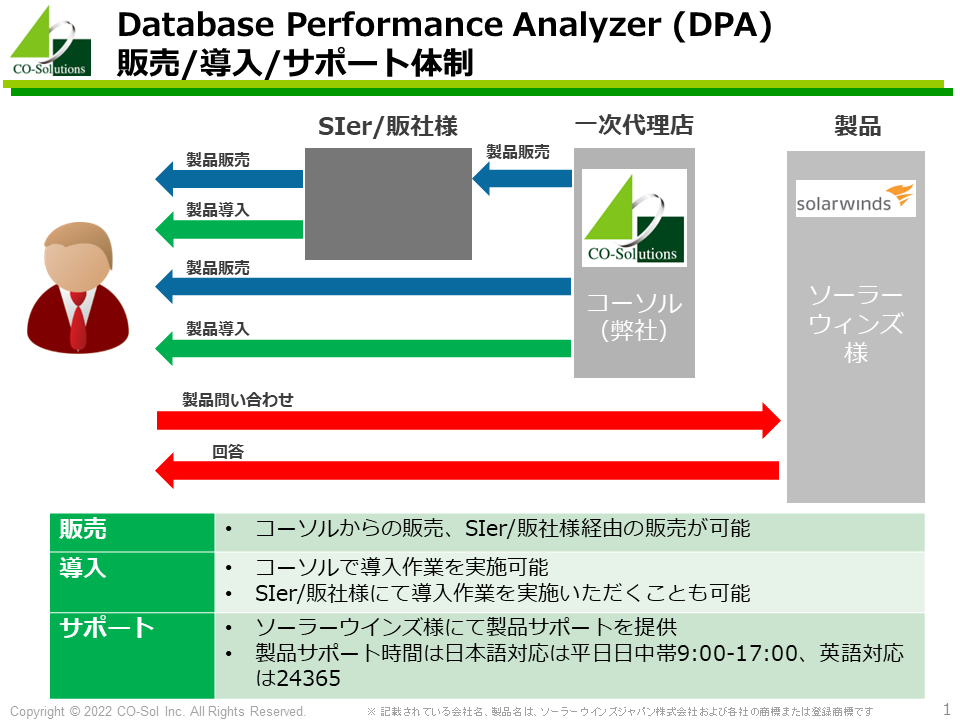
コーソルはDatabase Performance Analyzer (DPA)の一次代理店で、Database Performance Analyzer (DPA)の製品販売を行います。 SIer様、販社様がDatabase Performance Analyzer (DPA)を販売および導入することも可能です。
コーソルはデータベースの技術力を強みとしています。なかでもOracle Database技術力は日本随一です。MySQL、PostgreSQL、MS SQL Serverの資格や実績を持つエンジニアも多数在籍しております。
独自のDPAナレッジを公開
DPAの導入や監視設定に関する手順をナレッジとして公開しています。評価版をご利用される際の参考にしていただけると幸いです。
多数のOracle関連書籍を執筆

- [改訂2版] Oracleの基本 ~データベース入門から設計/運用の初歩まで : 渡部 亮太 , 舛井 智行, 岡野 平八郎, 峯岸 隆一, 日比野 峻佑, 相川潔
https://www.amazon.co.jp/dp/429712954X (2022年7月16日発売)
- オラクルマスター教科書 Gold DBA Oracle Database Administration II : 渡部 亮太 , 舛井 智行, 峯岸 隆一
https://www.amazon.co.jp/dp/479817436X/ (2022年5月27日 発売)
- オラクルマスター教科書 Silver SQL Oracle Database SQL : 渡部 亮太 , 舛井 智行, 峯岸 隆一
https://www.amazon.co.jp/dp/4798172367/ (2021年9月13日 発売)
- オラクルマスター教科書 Silver DBA Oracle Database Administration I : 渡部 亮太 , 舛井 智行 , 杉本 篤信 , 西田 幸平
https://www.amazon.co.jp/dp/4798166359/ (2021年5月28日 発売)
- オラクルマスター教科書 Bronze DBA Oracle Database Fundamentals : 渡部 亮太 , 岡野 平八郎 , 鈴木 俊也
https://www.amazon.co.jp/dp/4798166367/ (2020年9月17日 発売)
- オラクルマスター教科書 Gold Oracle Database 12c : 渡部 亮太 , 岡野 平八郎
https://www.amazon.co.jp/dp/4798147958/ (2018年8月8日 発売)
- Oracleの基本 ~ データベース入門から設計/運用の初歩まで : 渡部 亮太 , 相川 潔 , 日比野 峻佑 , 岡野 平八郎 , 宮川 大地
https://www.amazon.co.jp/dp/4774192511/ (2017年9月22日 発売)
- プロとしてのOracleアーキテクチャ入門【第2版】 : 渡部 亮太
http://www.amazon.co.jp/dp/4797384085/ (2015年4月25日 発売)
- プロとしてのOracle運用管理入門 : 渡部 亮太
http://www.amazon.co.jp/dp/4797355123/ (2009年9月25日 発売)
- プロとしてのOracleアーキテクチャ入門 : 渡部 亮太 , 森坂 康人
http://www.amazon.co.jp/dp/4797349808/ (2008年8月22日 発売)
- プロとしてのOracle入門 : 松下 雅, 舛井 智行, 古賀 加奈
http://www.amazon.co.jp/dp/4797349433/ (2008年10月29日 発売)
- Oracle Database 10g Oracle Enterprise Manager 逆引きクイックリファレンス : 舛井 智行, 青木 武士, 松下 雅
http://www.amazon.co.jp/dp/4797349433/ (2007年11月27日 発売)
ORACLE MASTER Platinum取得者数 No.1
- 単年度ORACLE MASTER Platinum取得者数7年連続No.1
7年連続ORACLE MASTER Platinum取得者数No.1! Oracle Certification Award 2020
- 累計ORACLE MASTER Platinum取得者数も、2016年以降No.1を維持
[PR] コーソルのデータベース運用関連製品とサービス
コーソルでは、データベース運用を製品とサービスでご支援します。
Database Performance Analyzer (DPA)
Database Performance Analyzer (DPA)は、オンプレミスとクラウド上の多くのデータベース製品に対応したデータベース性能管理製品です。低価格であるため、非常に導入しやすいです。
自動SQLチューニング機能を持つToad
Database Performance Analyzer (DPA)で検出された問題SQLをチューニングする際に、Toad for Oracle / Toad for SQL Serverの SQL Optimizer機能を使用できます。
リモートDBAサービス
リモートDBAサービスはDB・運用の専門家がお客様のデータベースに対して
必要な時に必要な対応を行うリモート接続型運用保守サービスです。
データベース運用保守なら常駐しないリモートDBA
時間制コンサルティングサービス
時間制コンサルティングサービスは”必要な時に” ”必要な時間だけ”契約できる
時間契約型のコンサルティングサービスです。
データベース コンサルティングなら時間制コンサルティング


