技術ブログ
技術ブログ
目次
2024年7月11日(木)~12日(金)で開催されたdb tech showcase 2024 Tokyoで、担当したセッション「SQL実行計画 - 主要RDBMS製品の比較(Oracle, MySQL, PostgreSQL)」の内容をご紹介しつつ、併せて、セッション資料のダウンロード方法、アーカイブ動画の視聴方法もご紹介させていただきます。
db tech showcaseは、株式会社インサイトテクノロジー様が主催する、国内最大級のデータ技術カンファレンスです。2012年から開催されています。
2024年のテーマは「テックギークに告ぐ。自らをファインチューニングせよ! - データ技術を鍛える100本ノック。これがdbtsの筋トレだ!- 」です!
なお、開催形式はフルオフライン形式のみでオンライン配信(ライブ)はありませんでしたが、後ほどご説明するアーカイブ配信サイトからアーカイブ動画を視聴できます。
db tech showcase 2024 Tokyoで、弊社からは以下のセッションをお送りしました。
Oracle, MySQL, PostgreSQLを対象に、実行計画に関連することがらを比較することで、データベースに関する理解を深めることを狙ったセッションです。 セッション全体としてのストーリーは特になく、気になった点をピックアップしてお話しする形で進めます。 いずれかのRDBMS製品の実行計画についてある程度の知識があることを前提とします。上級者向けのセッションと位置づけ、懇切丁寧には説明しません。

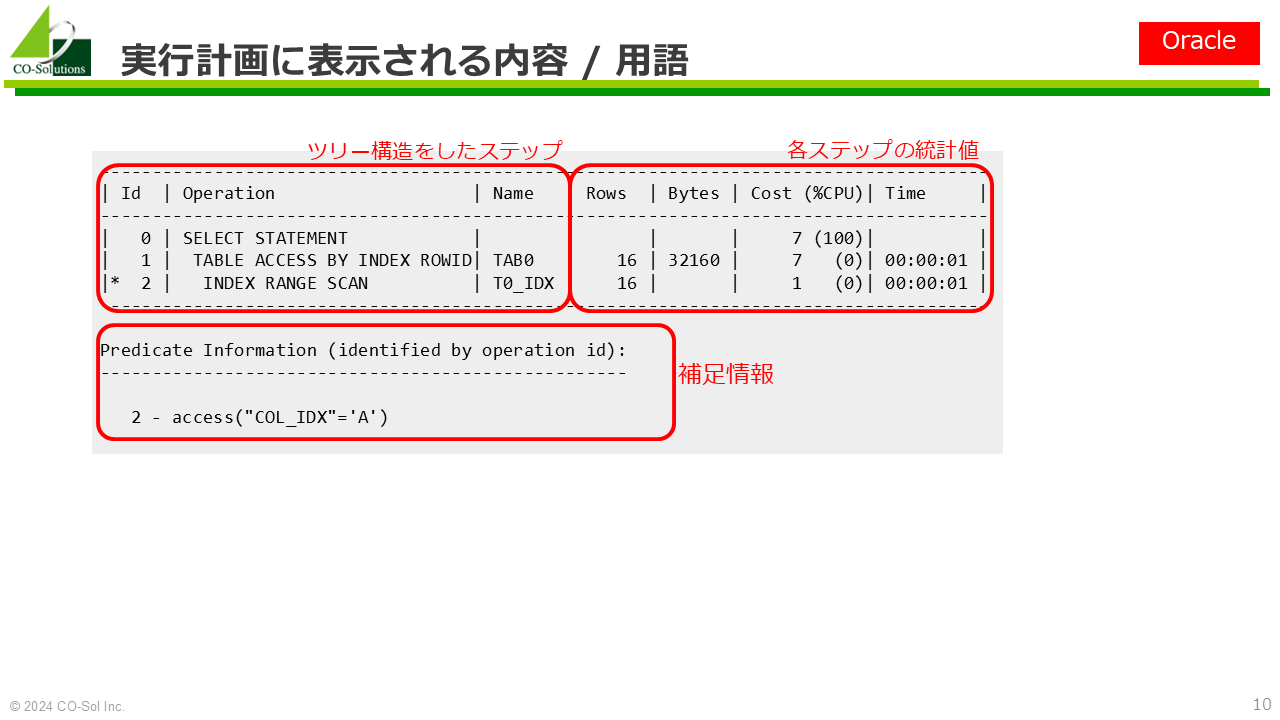
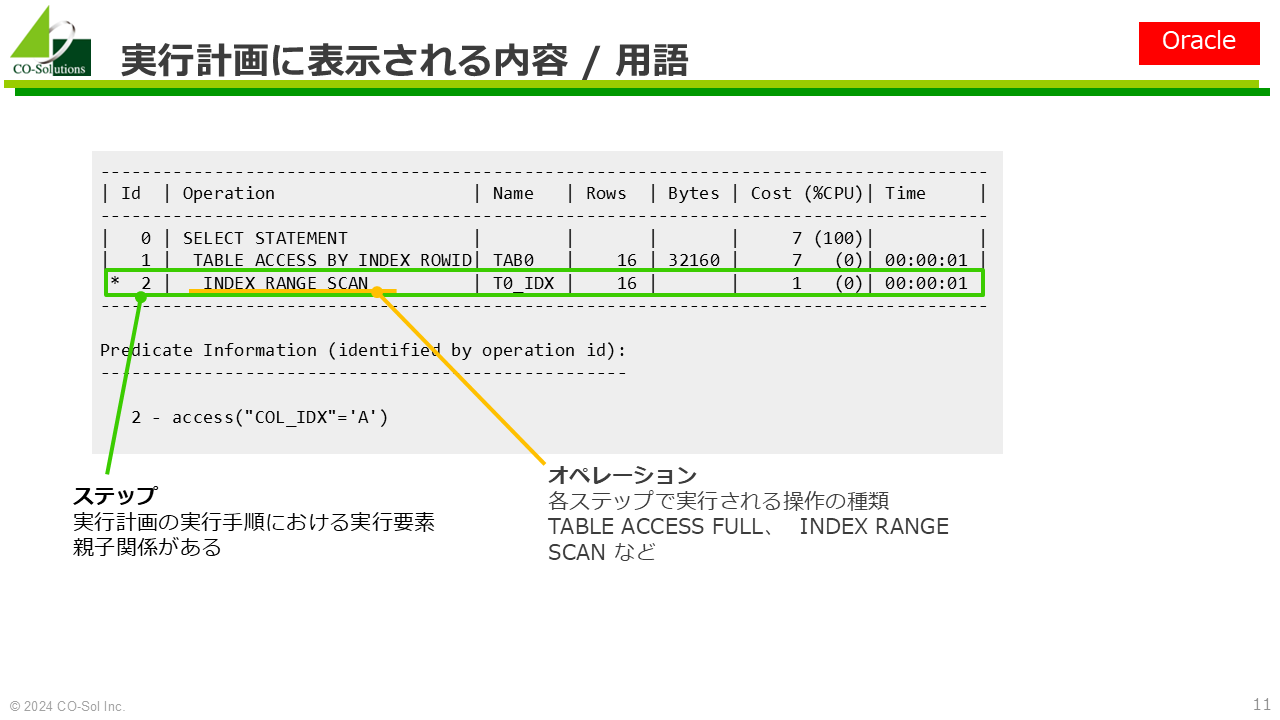
なお、使用される用語はRDBMS製品によって異なる。上記の語用は、Oracle Databaseのもの。

EXPLANコマンドを使用して実行計画を表示するが、詳細はRDBMS製品によって異なる
実行計画および統計には、見積(予測)と 実行時(実測)の2種類がある点に注意すること
→ 状況が許すなら、できるかぎり実行時実行計画を確認するべき

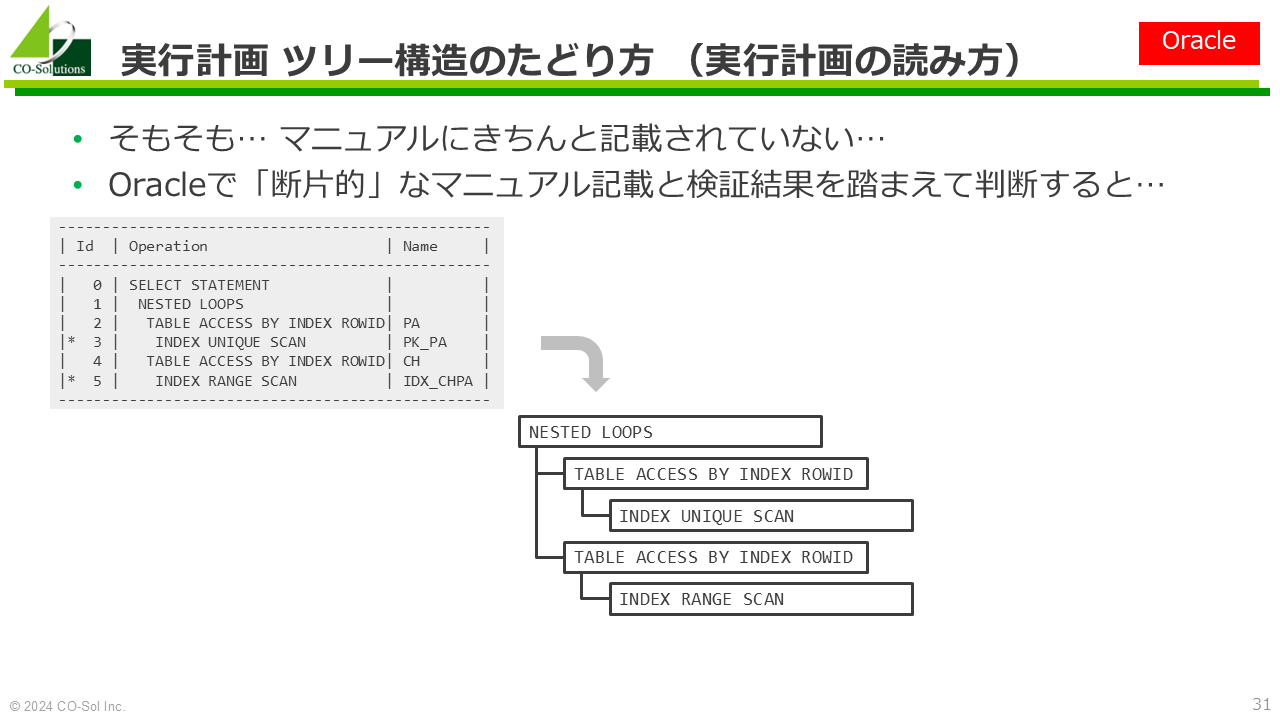
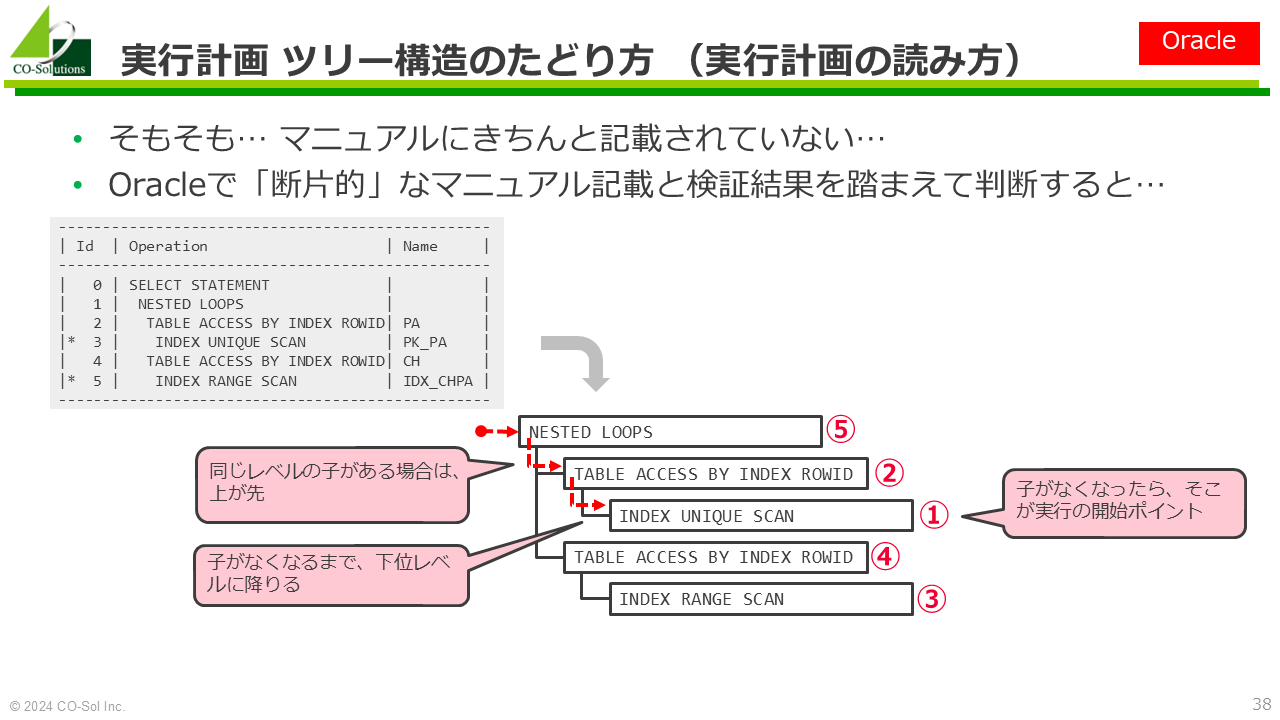
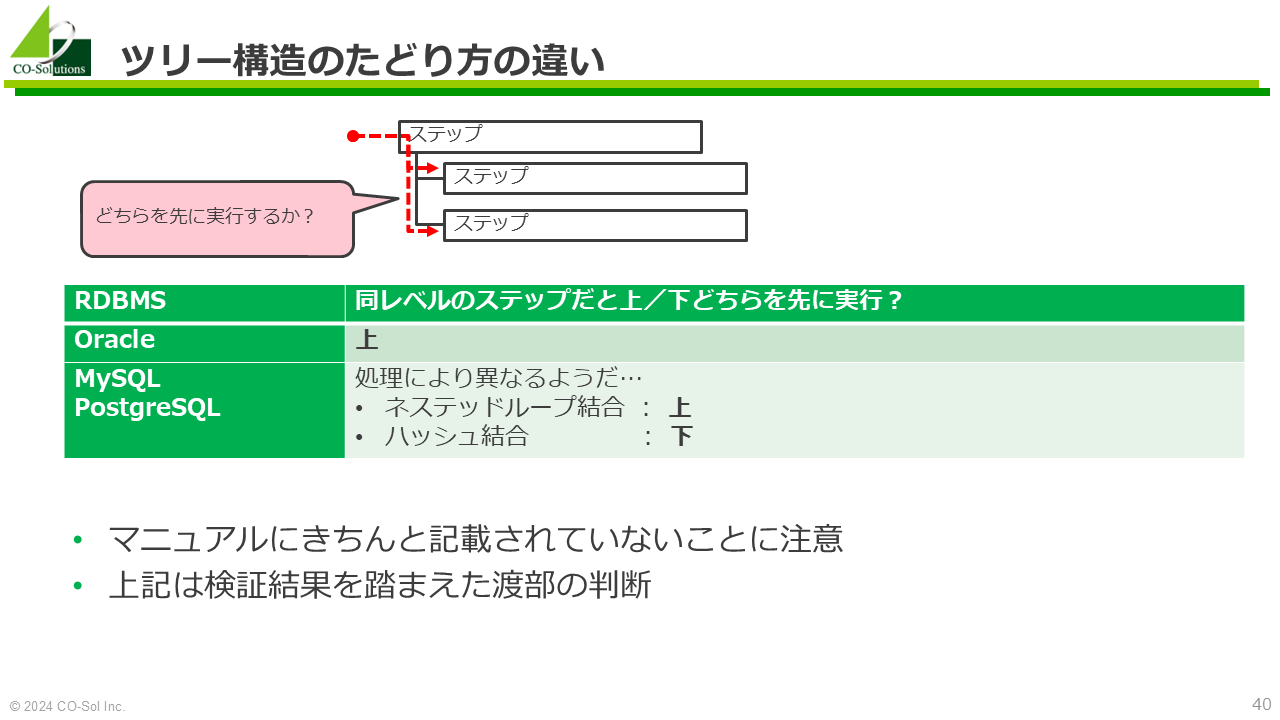
オペレーションに関するマニュアルの記載は、一般に十分ではない
「オペレーション」はOracle用語。PostgreSQLでは「クエリオペレータ」
念のための注意: 考え方が異なるので、オペレーションの種類の個数を単純に比較することはできない
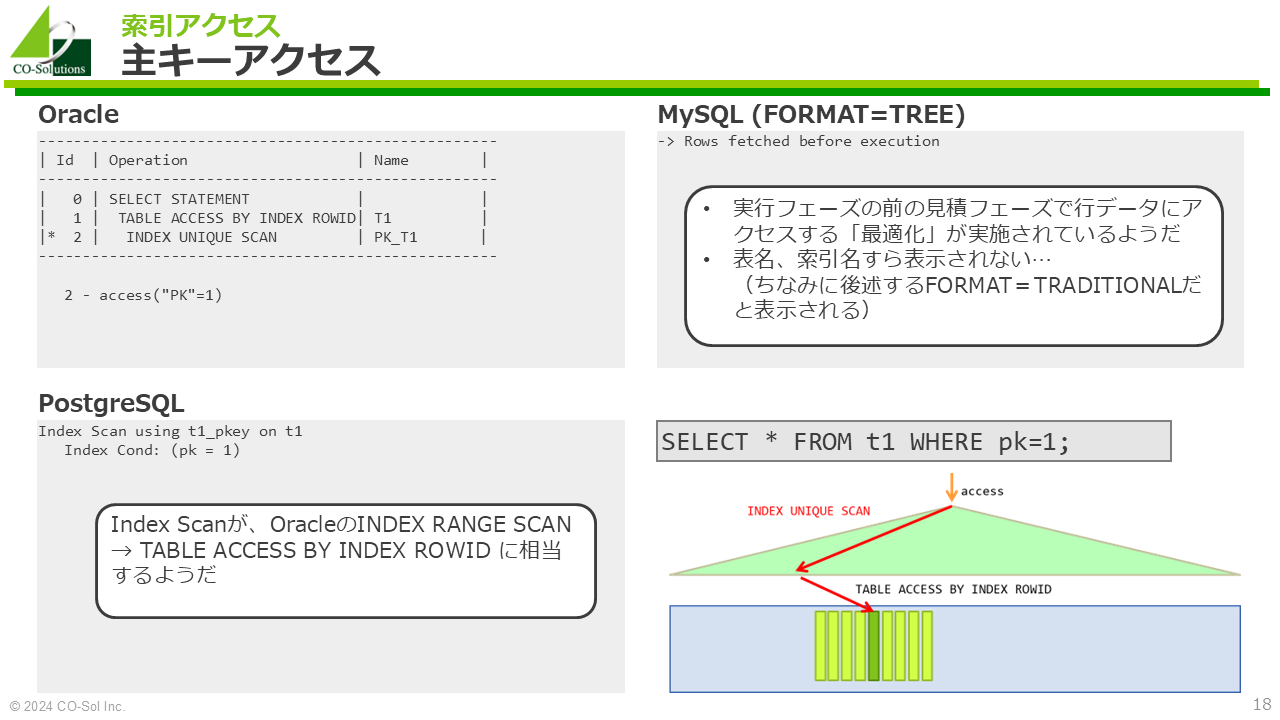
SELECT * FROM t1 WHERE pk=1;Oracle
----------------------------------------------------
| Id | Operation | Name |
----------------------------------------------------
| 0 | SELECT STATEMENT | |
| 1 | TABLE ACCESS BY INDEX ROWID| T1 |
|* 2 | INDEX UNIQUE SCAN | PK_T1 |
----------------------------------------------------
2 - access("PK"=1)MySQL (FORMAT=TREE)
-> Rows fetched before executionPostgreSQL
Index Scan using t1_pkey on t1
Index Cond: (pk = 1)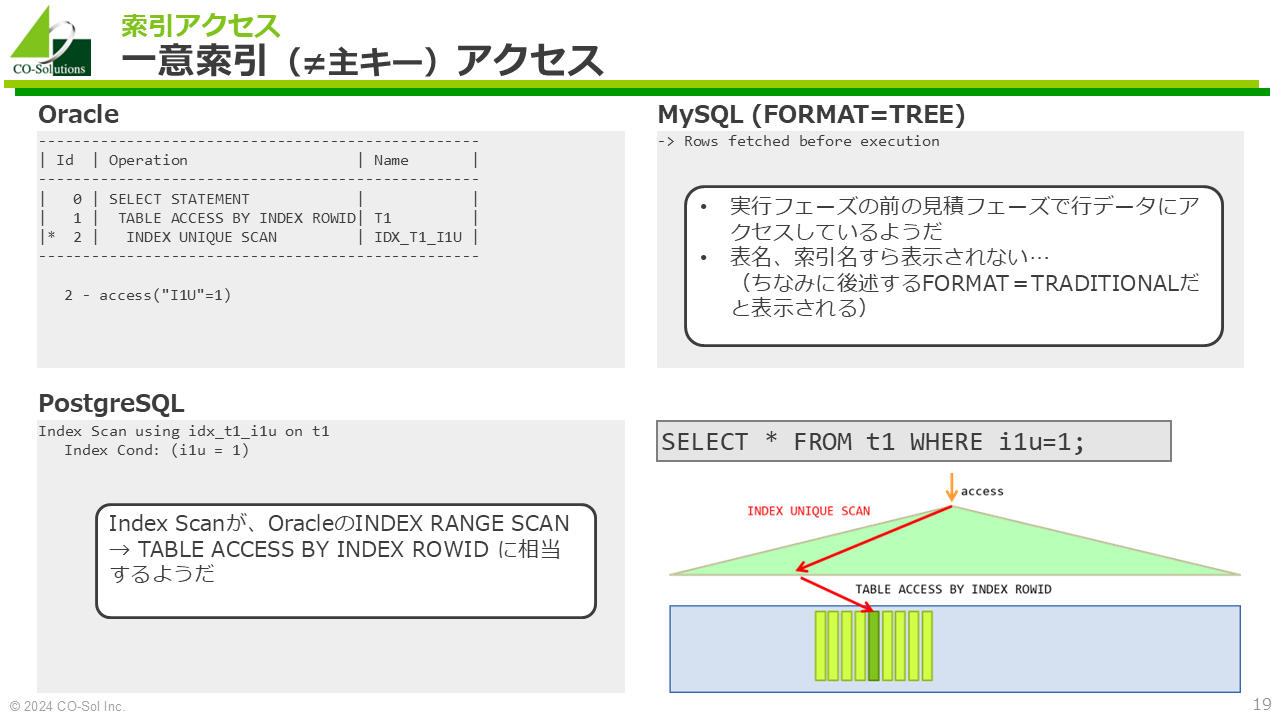
SELECT * FROM t1 WHERE i1u=1;Oracle
--------------------------------------------------
| Id | Operation | Name |
--------------------------------------------------
| 0 | SELECT STATEMENT | |
| 1 | TABLE ACCESS BY INDEX ROWID| T1 |
|* 2 | INDEX UNIQUE SCAN | IDX_T1_I1U |
--------------------------------------------------
2 - access("I1U"=1)MySQL (FORMAT=TREE)
-> Rows fetched before executionPostgreSQL
Index Scan using idx_t1_i1u on t1
Index Cond: (i1u = 1)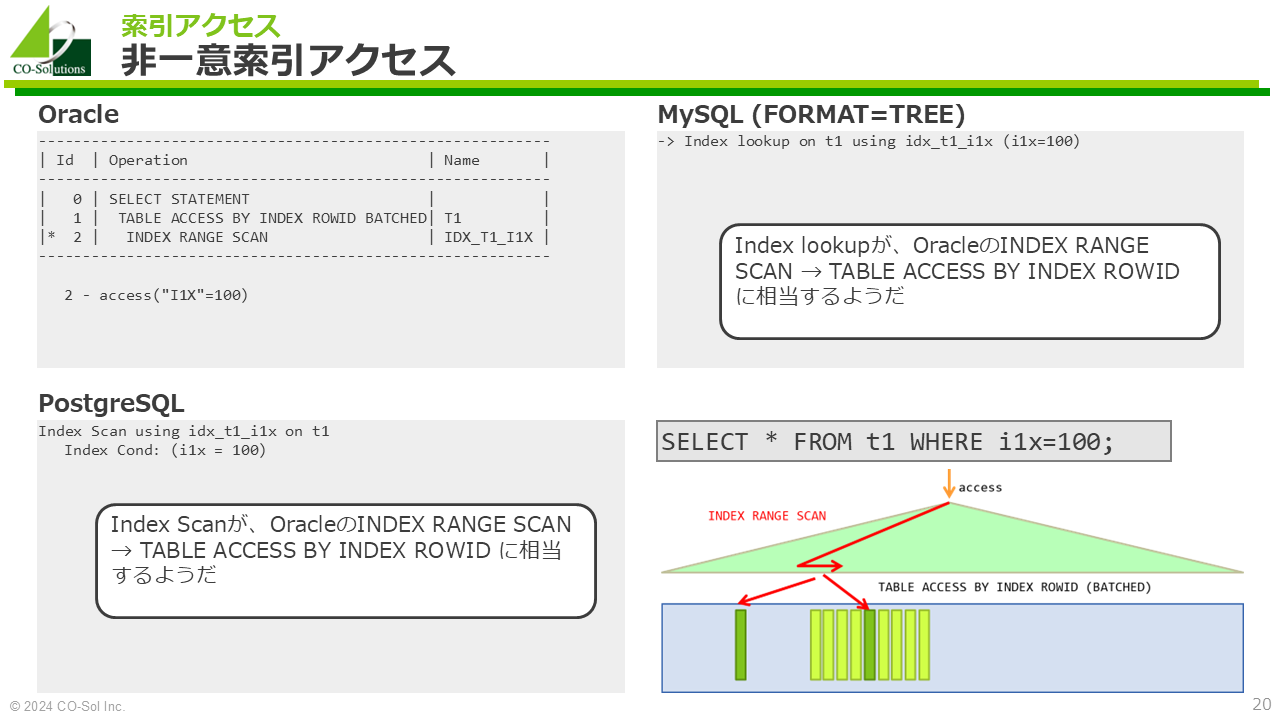
SELECT * FROM t1 WHERE i1u=1;Oracle
----------------------------------------------------------
| Id | Operation | Name |
----------------------------------------------------------
| 0 | SELECT STATEMENT | |
| 1 | TABLE ACCESS BY INDEX ROWID BATCHED| T1 |
|* 2 | INDEX RANGE SCAN | IDX_T1_I1X |
----------------------------------------------------------
2 - access("I1X"=100)MySQL (FORMAT=TREE)
-> Index lookup on t1 using idx_t1_i1x (i1x=100)PostgreSQL
Index Scan using idx_t1_i1x on t1
Index Cond: (i1x = 100)

本セッションでは、以下の理由でEXPLAIN FORMAT=TREEを中心に説明したが、若干過渡的な状況(EXPLAIN FORMAT=TRADITIONAL → EXPLAIN FORMAT=TREE)にあるのかもしれない。

上: FORMAT=TRADITIONAL / 下: FORMAT=TREE
主キーアクセス
+----+-------------+-------+------------+-------+---------------+---------+---------+-------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+---------+---------+-------+------+----------+-------+
| 1 | SIMPLE | t1 | NULL | const | PRIMARY | PRIMARY | 4 | const | 1 | 100.00 | NULL |
+----+-------------+-------+------------+-------+---------------+---------+---------+-------+------+----------+-------+-> Rows fetched before execution一意索引アクセス
+----+-------------+-------+------------+-------+---------------+------------+---------+-------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+------------+---------+-------+------+----------+-------+
| 1 | SIMPLE | t1 | NULL | const | idx_t1_i1u | idx_t1_i1u | 5 | const | 1 | 100.00 | NULL |
+----+-------------+-------+------------+-------+---------------+------------+---------+-------+------+----------+-------+-> Rows fetched before execution非一意索引アクセス
+----+-------------+-------+------------+------+---------------+------------+---------+-------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------------+---------+-------+------+----------+-------+
| 1 | SIMPLE | t1 | NULL | ref | idx_t1_i1x | idx_t1_i1x | 5 | const | 1 | 100.00 | NULL |
+----+-------------+-------+------------+------+---------------+------------+---------+-------+------+----------+-------+-> Index lookup on t1 using idx_t1_i1x (i1x=100)
上: FORMAT=TRADITIONAL / 下: FORMAT=TREE
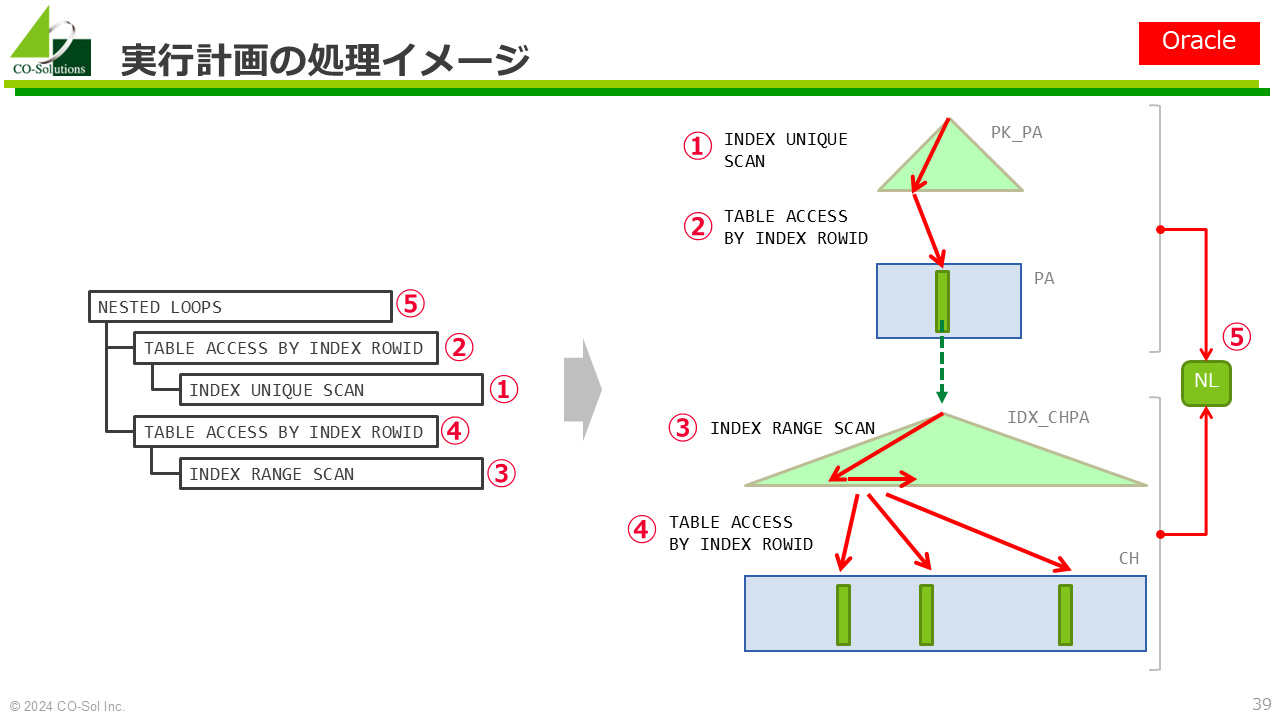
ネステッドループ結合
+----+-------------+-------+------------+--------+--------------------------------------+------------+---------+---------------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+--------+--------------------------------------+------------+---------+---------------+------+----------+-------------+
| 1 | SIMPLE | t3 | NULL | ref | idx_t3_i3x,idx_t3_i3y,idx_t3_i3x_i3y | idx_t3_i3y | 5 | const | 45 | 100.00 | Using where |
| 1 | SIMPLE | t1 | NULL | eq_ref | idx_t1_i1u | idx_t1_i1u | 5 | testdb.t3.i3x | 1 | 100.00 | NULL |
+----+-------------+-------+------------+--------+--------------------------------------+------------+---------+---------------+------+----------+-------------+-> Nested loop inner join
-> Filter: (t3.i3x is not null)
-> Index lookup on t3 using idx_t3_i3y (i3y=1)
-> Single-row index lookup on t1 using idx_t1_i1u (i1u=t3.i3x)ハッシュ結合
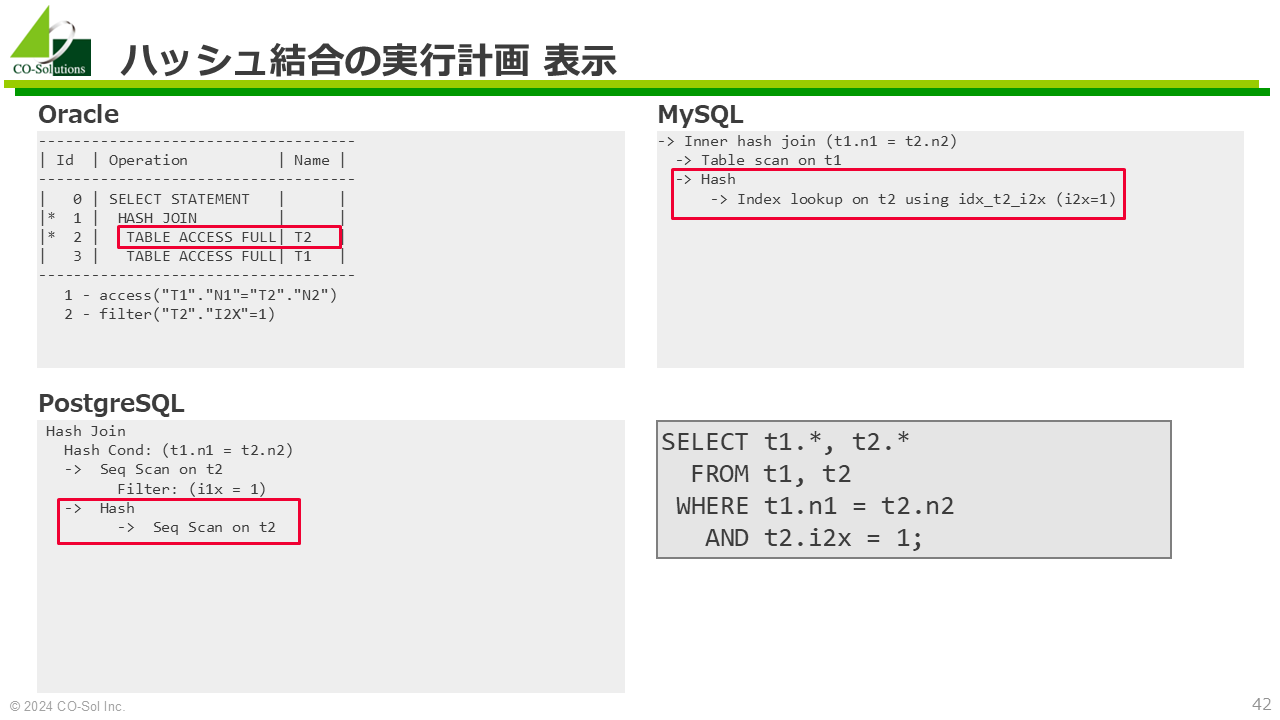
+----+-------------+-------+------------+------+---------------------------+------------+---------+-------+------+----------+--------------------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------------------+------------+---------+-------+------+----------+--------------------------------------------+
| 1 | SIMPLE | t2 | NULL | ref | idx_t2_i2x,idx_t2_i2x_i2y | idx_t2_i2x | 5 | const | 450 | 100.00 | NULL |
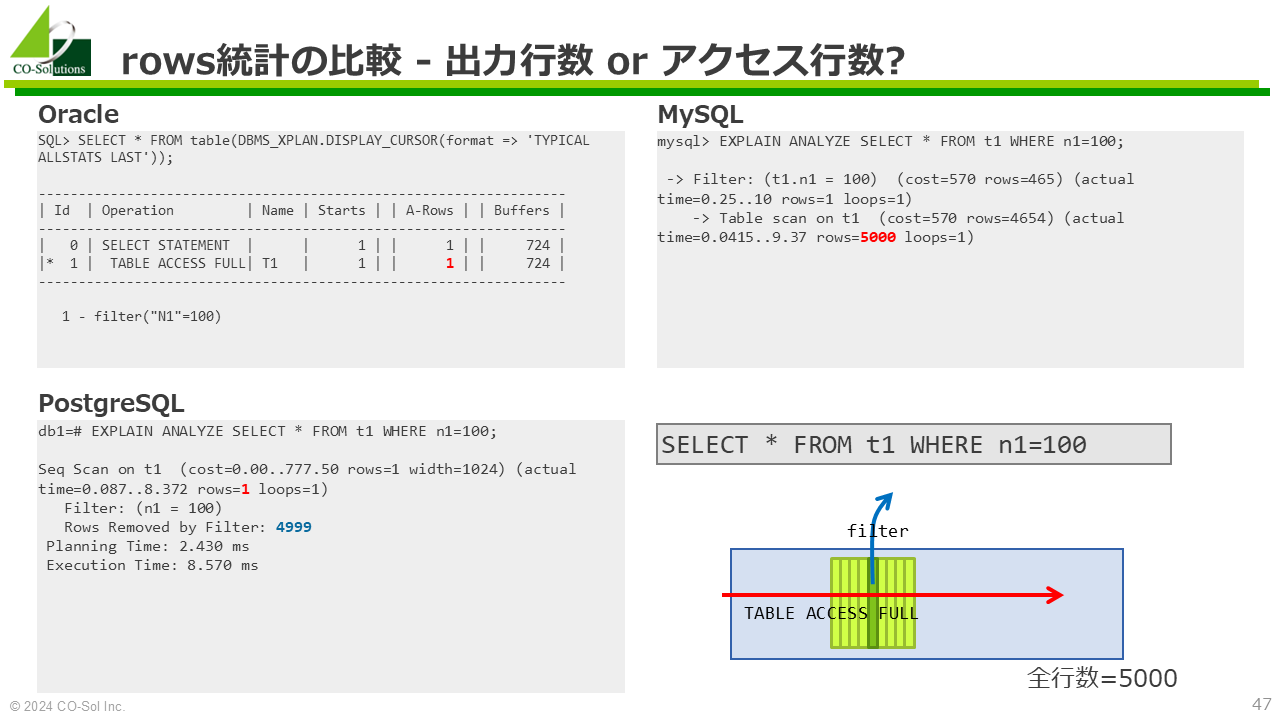
| 1 | SIMPLE | t1 | NULL | ALL | NULL | NULL | NULL | NULL | 4654 | 10.00 | Using where; Using join buffer (hash join) |
+----+-------------+-------+------------+------+---------------------------+------------+---------+-------+------+----------+--------------------------------------------+-> Inner hash join (t1.n1 = t2.n2)
-> Table scan on t1
-> Hash
-> Index lookup on t2 using idx_t2_i2x (i2x=1)

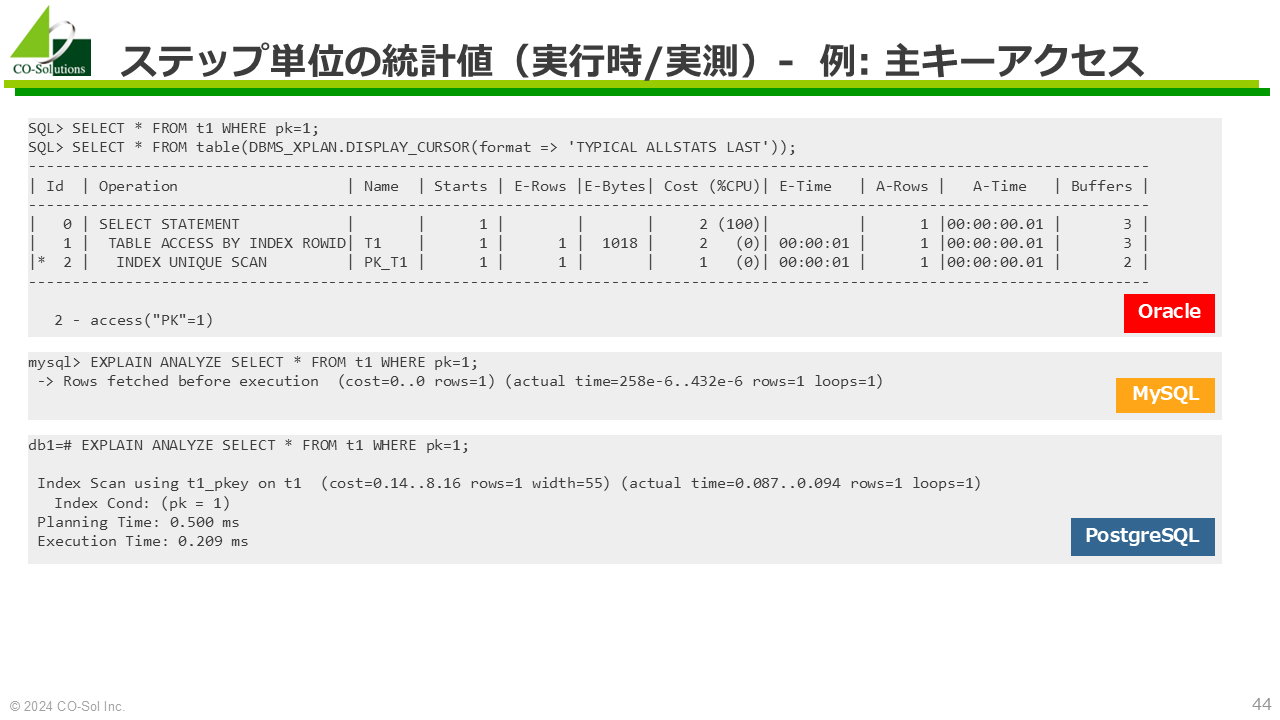
SQL> SELECT * FROM t1 WHERE i1u=1;
SQL> SELECT * FROM table(DBMS_XPLAN.DISPLAY_CURSOR);
PLAN_TABLE_OUTPUT
--------------------------------------------------------------------------------------------
SQL_ID aqry97d8kxgas, child number 0
-------------------------------------
SELECT * FROM t1 WHERE i1u=1
Plan hash value: 2661144773
------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | | | 2 (100)| |
| 1 | TABLE ACCESS BY INDEX ROWID| T1 | 1 | 1018 | 2 (0)| 00:00:01 |
|* 2 | INDEX UNIQUE SCAN | IDX_T1_I1U | 1 | | 1 (0)| 00:00:01 |
------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("I1U"=1)SQL_ID: SQLの識別子(≒SQL文字列のハッシュ値)
Plan hash value: 実行計画の識別子
SQLおよび実行計画の同一性を簡単にチェックできるため、非常に便利



資料は、弊社の資料ダウンロードページ(要登録+DM配信同意)からダウンロードできます。
セッション動画は、db tech showcaseのアーカイブ配信サイトから視聴できますが、 db tech showcase 2024 Tokyoへの登録状況によって、視聴までの手順が異なる点に注意が必要です。
私が確認した限り、セッション動画はYouTubeを使って配信されているようで、再生速度の調整や自動生成された字幕の表示が可能なようです。便利!
「主要RDBMS製品の比較」ページ一覧
過去発表と発表資料
12/6 #dbts2023 「主要4種データベース製品(Oracle、MySQL、PostgreSQL、MS SQL Server)の相違点比較と異種データベース製品活用における課題と解決」セミナーのお知らせ
7/11 #dbts2024 「SQL実行計画 – 主要RDBMS製品の比較(Oracle, MySQL, PostgreSQL)」セミナーのお知らせ
バックアップと障害復旧から考えるOracle Database, MySQL, PostgreSQLの違い
資料は、弊社の資料ダウンロードページ(要登録+DM配信同意)からダウンロードできます。
立場の表明



Database Performance Analyzer (DPA) は、オンプレミス&クラウドに対応するデータベース性能監視/分析ツールです。
この記事で取り上げたRDBMS製品を含む、非常に多くのデータベース製品/サービスに対応しています。
以下の特徴があり、導入しやすく有用な製品です。
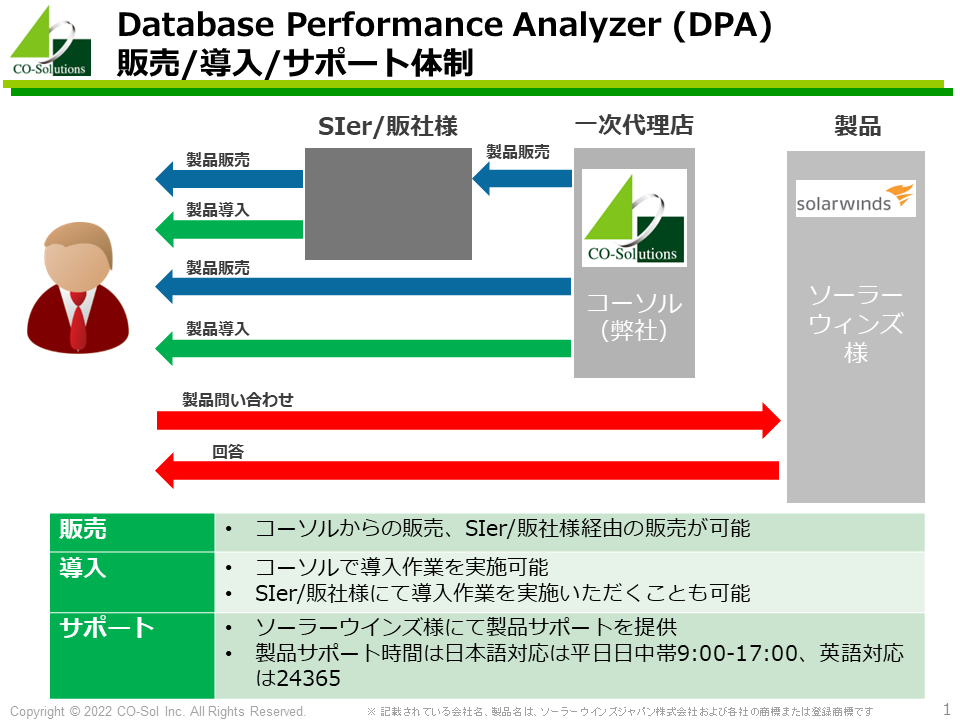
コーソルはDatabase Performance Analyzer (DPA)の一次代理店で、Database Performance Analyzer (DPA)の製品販売を行います。 SIer様、販社様がDatabase Performance Analyzer (DPA)を販売および導入することも可能です。
コーソルはデータベースの技術力を強みとしています。なかでもOracle Database技術力は日本随一です。MySQL、PostgreSQL、MS SQL Serverの資格や実績を持つエンジニアも多数在籍しております。
DPAの導入や監視設定に関する手順をナレッジとして公開しています。評価版をご利用される際の参考にしていただけると幸いです。

7年連続ORACLE MASTER Platinum取得者数No.1! Oracle Certification Award 2020
コーソルでは、データベース運用を製品とサービスでご支援します。
Database Performance Analyzer (DPA)は、オンプレミスとクラウド上の多くのデータベース製品に対応したデータベース性能管理製品です。低価格であるため、非常に導入しやすいです。
Database Performance Analyzer (DPA)で検出された問題SQLをチューニングする際に、Toad for Oracle / Toad for SQL Serverの SQL Optimizer機能を使用できます。
リモートDBAサービスはDB・運用の専門家がお客様のデータベースに対して 必要な時に必要な対応を行うリモート接続型運用保守サービスです。
データベース運用保守なら常駐しないリモートDBA
時間制コンサルティングサービスは”必要な時に” ”必要な時間だけ”契約できる 時間契約型のコンサルティングサービスです。
データベース コンサルティングなら時間制コンサルティング



プロフィール
渡部 亮太
・Oracle ACE
・AWS Certified Solutions Architect - Associate
・ORACLE MASTER Platinum Oracle Database 11g, 12c 他多数
カテゴリー
アーカイブ
2026年
2025年
2024年
2023年
2022年
2021年
2020年
2019年
2018年
2017年
2016年
2015年
2014年
2013年
2012年
2000年